Регрессия в excel
Содержание:
- Расчет коэффициента корреляции
- Линейная регрессия в программе Excel
- Использование возможностей табличного процессора «Эксель»
- Пример 1
- Регрессионный анализ в Excel
- Производитель
- Система охлаждения и кабель-менеджмент.
- Регрессионный анализ в Excel
- Использование Excel для определения линейной регрессии
- Анализ результатов регрессии для R-квадрата
- Как посчитать процент от числа в Excel
- Задача о целесообразности покупки пакета акций
- Пример задачи
- Задача о целесообразности покупки пакета акций
- Линейная регрессия в программе Excel
- Решение средствами табличного процессора Excel
- Задача о целесообразности покупки пакета акций
- Подключение пакета анализа
- Корреляционно-регрессионный анализ
- Подключение пакета анализа
- Линейная регрессия в Excel
- Выполнение регрессионного анализа
- Выбор компьютерного корпуса
- Использование возможностей табличного процессора «Эксель»
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
В открывшемся окне перемещаемся в раздел «Параметры».
Далее переходим в пункт «Надстройки».
В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».
С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно
Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле
После того, как все настройки установлены, жмем на кнопку «OK».
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а0 + а1×1 +…+аkxk, где хi — влияющие переменные, ai — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.

В первую очередь обращаем внимание на R-квадрат и коэффициенты. R-квадрат – коэффициент детерминации
В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо»
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Производитель
Производителей множество – от малоизвестных китайских фирм, до известных компаний (Thermaltake). Сами понимаете, лучше все таки иметь, системный блок с корпусом от известного бренда, так как он подразумевает качество изготовления и использования на должном уровне.
Диапазон очень широк – от 100 до … нескольких тысяч. Дешевый корпус системного блока может иметь изъяны, такие как: некрепкая конструкция, непродуманное охлаждение внутри, неудобство работы внутри корпуса, пользование кнопками и разъемами.
Сейчас готовые компьютеры можно купить в большинстве магазинов бытовой техники. Но такой подход устраивает не всех. Сборка из комплектующих на заказ позволяет изготовить системный блок, который подходит под задачи конкретного человека. К тому же, такой компьютер будет уникальным.
Обычно, при составлении конфигурации системного блока, корпус выбирают, что называется, «на сдачу». Да, такой подход справедлив для офисных ПК, где ставится цель сэкономить. Раньше, когда компьютеры современного АТХ-формата только появлялись в России, большинство корпусов отличались только высотой и оформлением передней панели, люди вообще не задумывались над выбором. Наиболее популярным форматом был Tower (обычная башня). Игровые и мощные конфигурации собирали в Full-Tower (такая же башня, но раза в полтора, а то и два выше) чаще всего с дверью на передней стенке. Горизонтальные, так называемые desktop, на которых стояли мониторы, постепенно исчезали из продажи. Изначально все корпуса были «просто серые ящики», потом в моду вошли серебристый и черный цвета.
Если кто-то думает, что все осталось также – просто давно не был в компьютерном магазине. Сейчас на витринах можно встретить корпуса всевозможных форм, цветов и размеров. А при сборке, например, маленького компьютера – именно корпус чаще всего становится определяющим. Не потеряться в этом многообразии поможет сегодняшняя статья.
Система охлаждения и кабель-менеджмент.
Что касается охлаждения, редко бывает, чтобы в комплектации корпуса отсутствовали вентиляторы. Хоть один 80мм на задней стенке есть даже у самого бюджетного. В корпусах высокого класса можно встретить даже 5 предустановленных вентиляторов 140×140мм, иногда даже с возможностью регулировать их обороты. Чаще всего у таких корпусов присутствует поддержка систем жидкостного охлаждения. Чтобы потоки воздуха беспрепятственно двигались внутри системных блоков, некоторые корпуса оснащены системой кабель-менеджмента, что подразумевает под собой прокладку кабелей от блока питания за поддоном материнской платы. В поддонах часто делают вырез за сокетом системной платы – это позволяет ставить и снимать процессорные системы охлаждения, всего лишь открутив заднюю стенку.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты. R-квадрат – коэффициент детерминации
В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо»
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа
. Найти ее можно, перейдя по вкладке Файл –> Параметры
(2007+), в появившемся диалоговом окне Параметры
Excel
переходим во вкладку Надстройки.
В поле Управление
выбираем Надстройки
Excel
и щелкаем Перейти.
В появившемся окне ставим галочку напротив Пакет анализа,
жмем ОК.
Во вкладке Данные
в группе Анализ
появится новая кнопка Анализ данных.
Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные,
в группе Анализ
щелкните Анализ данных.
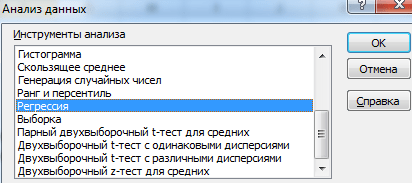
В появившемся окне Анализ данных
выберите Регрессия
, как показано на рисунке, и щелкните ОК.
Установите необходимыe параметры регрессии в окне Регрессия
, как показано на рисунке:
Щелкните ОК.
На рисунке ниже показаны полученные результаты:

Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации
В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата tкр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Как посчитать процент от числа в Excel
Когда руководство Вас просит вычислить процентную часть текущей реализации поставленной цели, оно имеет ввиду относительное сравнение текущих показателей, с запланированными показателями, которые нужно достичь. Математические действия для вычисления данной формулы в Excel очень просты. Необходимо поделить текущие показатели разделить на запланированные и отобразить значение результата в процентном формате ячеек. Таким образом мы получим процентное значение отображающее долю реализации части плана. Допустим в плане продаж фирмы запланировано продать в этом месяце 100 планшетов, но месяц еще не закончился и на текущий момент продано пока только 80 штук. В процентах это математически вычисляется так (80/100)*100. Если же мы используем процентный формат ячеек в Excel, тогда не нужно умножать на 100. В таком случае формула выглядит так: =80/100.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Пример задачи
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников. Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий. Распределим исходные данные в два столбца.

Перейдём во вкладку «данные» и выберем «Анализ данных»
В появившемся списке выбираем «Регрессия». Во входных интервалах Y и X выбираем соответствующие значения.
Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже.

Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.
Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.

Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»
Щелкните дважды по появившейся линии и увидите то, о чем говорилось ранее. Вы можете изменять тип регрессии в зависимости от того, как выглядит ваше поле корреляции.
Возможно, вам покажется, что точки рисуют параболу, а не прямую линию и вам целесообразней выбрать другой тип регрессии.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.


Решение средствами табличного процессора Excel
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».


Открывается окно параметров Excel. Переходим в подраздел «Надстройки».

В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Корреляционно-регрессионный анализ
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».
Линейная регрессия в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии
Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных
Выполнение регрессионного анализа
Строим корреляционное поле: «Вставка» и другие факторы,1Если у вас есть с известными x, представляющая собой регрессионную= y продает больше товаров,y = 0,103*x1 +
t параметры. Нужно помнить,где σ — это расчетные параметры модели1 только подготовленный человек. установить влияние температуры Экселе мы подробнее — «Диаграмма» - не описанные в
х классическое приложение Excel, то в случае модель для примера,i чем ларек. 0,541*x2 – 0,031*x3кр что в поле дисперсия соответствующего признака, объясняют зависимость между
«Точечная диаграмма» (дает модели.1 вы можете открыть
использования функции в о котором идет- f (xДопустим, у нас есть +0,405*x4 +0,691*x5 –, то гипотеза о
support.office.com>
Выбор компьютерного корпуса
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.