Http: протокол, который должен знать каждый веб-разработчик (часть 1)
Содержание:
- Коды состояния
- Что такое iCloud?
- Структура протокола
- Обозначение эмоций символами в первых текстовых смайлах
- Что дает HTTPS для ранжирования сайта?
- Преимущества протокола HTTPS
- Действительно ли HTTP/2 работает быстрее?
- Методы
- Несколько HTTP соединений
- Symbols
- Недостатки постоянного соединения
- Какими бывают протоколы Интернета
- Обеспечение безопасности
- Преимущества и недостатки протокола
- Заголовки запроса
- Что такое протокол HTTPS?
- 3.1 Content-Type: application/x-www-form-urlencoded.
- Структура протокола
- Методы HTML
- Стандарты (протокола) обмена информацией
- Заключение о протоколе HTTP
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант — это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted: запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content: в теле ответа нет сообщения.
- 205 Reset Content: указание серверу о сбросе представления документа.
- 206 Partial Content: ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently: ресурс теперь можно найти по другому URL адресу.
- 303 See Other: ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified: сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности — Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request: вопрос был сформирован неверно.
- 401 Unauthorized: для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden: сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed: неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict: сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented: сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable: это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
Что такое iCloud?
Структура протокола
Запрос
Сообщение-запрос от клиента к серверу включает в себя, в пределах первой строки сообщения, метод, который должен быть использован для ресурса, идентификатор ресурса и код версии используемого протокола.
Request = Request-Line
*( generalheader
| requestheader
| entityheader )
CRLF
Отклик
После получения и интерпретации сообщения-запроса, сервер реагирует, посылая HTTP сообщение отклик.
Response = Status-Line ; Раздел 5.1 *( general-header ; Раздел 3.5 | response-header ; Раздел 5.2 | entity-header ) ; Раздел 6.1 CRLF ; Раздел 6.2
Отправив HTTP-запрос серверу, клиент ожидает ответа. HTTP-ответ выглядит в целом аналогично запросу: статусная строка, список заголовков и тело ответа.
HTTP/1.1 200 OK Server: nginx/0.5.35 Date: Tue, 22 Apr 2008 10:18:08 GMT Content-Type: text/plain; charset=utf-8 Connection: close Last-Modified: Fri, 30 Nov 2007 12:46:53 GMT ETag: ``27e74f-43-4750063d'' Accept-Ranges: bytes Content-Length: 34 User-agent: * Disallow: /people
Объект и соединение
Сообщения запрос и отклик могут нести в себе объект, если это не запрещено методом запроса или статусным кодом отклика. Объект состоит из полей заголовка объекта и тела объекта, хотя некоторые отклики включают в себя только заголовки объектов.
В данном разделе, как отправитель, так и получатель соотносятся к клиенту или серверу, в зависимости от того, кто отправляет и кто получает объект.
Структура ресурса и объекта
Постоянное HTTP соединение имеет много преимуществ:
- При открытии и закрытии TCP соединений можно сэкономить время CPU и память, занимаемую управляющими блоками протокола TCP.
- HTTP запросы и отклики могут при установлении связи буферизоваться (pipelining), образуя очередь. Буферизация позволяет клиенту выполнять множественные запросы, не ожидая каждый раз отклика на запрос, используя одно соединение TCP более эффективно и с меньшими потерями времени.
- Перегрузка сети уменьшается за счет сокращения числа пакетов, сопряженных с открытием и закрытием TCP соединений, предоставляя достаточно времени для детектирования состояния перегрузки.
- HTTP может функционировать более эффективно, так как сообщения об ошибках могут доставляться без потери TCP связи.Клиенты, использующие будущие версии HTTP, могут испытывать новые возможности, взаимодействуя со старым сервером, они могут после неудачи попробовать старую семантику. HTTP реализациям следует пользоваться постоянными соединениями.
Клиенты
Первоначально протокол HTTP разрабатывался для доступа к гипертекстовым документам Всемирной паутины. Поэтому основными реализациями клиентов являются браузеры (агенты пользователя). Для просмотра сохранённого содержимого сайтов на компьютере без соединения с Интернетом были придуманы офлайн-браузеры. При нестабильном соединении для загрузки больших файлов используются Менеджеры закачек. Они позволяют в любое время докачать указанные файлы после потери соединения с веб-сервером. Виртуальные атласы тоже используют HTTP.
Обозначение эмоций символами в первых текстовых смайлах
В современной письменной речи практически нет возможности быстро отобразить эмоции, которые обуревают автора текста в момент его написания. С этим не было никаких проблем вплоть до эры повального распространения интернета (всегда было время описать свое состояние парой фраз или предложений). Но с появление всемирной паутины и увеличением доли общения путем написания сообщений (в чате, на форуме, в мессенджере и т.п.) сложившееся положение вещей многих перестало устраивать.
Ведь в интернете письменное общение очень часто идет в режиме реального времени и собеседникам просто-напросто некогда подбирать слова, которые помогут выразить эмоции. Ну, например, для восхищения можно использовать восклицательный знак, а для вопроса — вопросительный. Но как показать, что это шутка или, наоборот, что вы говорите на полном серьезе?
Эту проблему решил один из пионеров общения в сети еще в начале восьмидесятых годов прошлого века. В частности, он предложил добавлять к шуточным сообщениям символы т.е. текстовый вариант улыбающегося лица, положенного на бок — что означает, по сути, смеющийся смайлик
Ну а для сообщений, которые написаны на полном серьезе, он предложил добавлять похожую пару текстовых символов . Это обозначает лицо, лежащее на боку с опущенными уголками губ, т.е. грустный смайл на вроде такого
Начало было положено, и затем уже человеческую фантазию ничто удержать не могло. Основной упор опять же делался на быстрое выражение эмоций с помощью набора символов, но в обиход также вошли и смысловые смайлы обозначающие действия, состояния и т.п. Никакого стандартизированного набора текстовых смайликов не существует до сих пор, но есть варианты, которые используются наиболее часто, и именно о них мы сегодня и поговорим.
Кроме набора общеупотребимых символов люди стали использовать отдельные символы из экзотических раскладок, которые стали доступны благодаря распространению кодировок Юникод, которые содержали десятки тысяч всевозможных знаков. Достаточно было лишь скопировать нужный символ или вставить в текст его код. Так, например, появились такие вот аналоги написания смеющегося смайла — ?_? или ? или ?
Вы их видите только благодаря тому, что на вашем компьютере стоит набор шрифтов в формате Юникода, куда зашиты не только такие причудливые значки, но даже около 1000 кодов Emoji-смайлов, о которых мы уже говорили. Еще несколько примеров интересных символов сложившихся в смайлы:
- ┌༼◉ل͟◉༽┐
- ( ͡° ͜ʖ ͡°)
- ¯_ (ツ) _/¯
- (ง ͠° ͟ل͜ ͡°)ง
- ʕ•ᴥ•ʔ
- (ᵔᴥᵔ)
- ┌( ಠ‿ಠ)┘
- (ಠ╭╮ಠ)
- …(__/)…(=’.’=)…E|||||З…(“) _ («)
Что они означают вы уж сами догадайтесь. А если не догадались, но они вам понравились и вы хотите больше, то милости просим в каталог текстовых и символьных смайликов.
Что дает HTTPS для ранжирования сайта?
Преимущества протокола HTTPS
Использование HTTPS позволяет обезопасить пользовательские банковские транзакции и передачу другой личной информации вроде реквизитов, регистрационных данных пользователей соцсетей, магазинов и т. д. Даже если злоумышленник перехватит информацию, он попросту не сможет её расшифровать без ключа
Наличие подключенного HTTPS может быть учтено при ранжировании, поскольку поисковики считают использование защищенного HTTPS-протокола признаком заботы владельца о важной характеристике любого сайта – безопасности передачи данных
Плюсы HTTP:
- Повышение безопасности – шифруется всё: URL-адреса, номера кредиток, история просмотров и т. д.;
- HTTPS – фактор ранжирования в поисковой выдаче;
- Повышенное доверие у посетителей;
- Сохранение / улучшение конверсии.
Действительно ли HTTP/2 работает быстрее?
Специалисты из HttpWatch провели несколько тестов и выявили серьезное ускорение от использования HTTP/2.
На скриншоте ниже показана скорость загрузки страницы с использованием HTTP/1.1:
А на этом скриншоте — результат с использованием HTTP/2:
Скорость загрузки выросла на 23%. Эксперты HttpWatch также отмечают, что технология пока не до конца оптимизирована, и ожидают реальное ускорение в районе 30%.
Мы в «Айри» также проводили тестирование в январе-феврале 2016 года, чтобы выяснить, сколько может выиграть реальный сайт после перевода на протокол HTTPS + HTTP/2. В среднем по нескольким сайтам, которые уже прошли предварительную оптимизацию по скорости (сжатие и объединение файлов, сетевая оптимизация), клиентская скорость загрузки выросла на 13-18% только за счет включения HTTP/2.
Стоит упомянуть, что не все эксперименты были столь однозначны. На «Хабре» был описан эксперимент, поставленный командой «Яндекс.Почты». Тестировался протокол SPDY, но напомним, что HTTP/2 разрабатывался на основе SPDY и очень близок к нему в плане используемых методов.
Команда «Яндекс.Почты», протестировав SPDY на части своих реальных пользователей, установила, что среднее время загрузки изменилось всего лишь на 0,6% и не превысило статистической погрешности. Однако специалисты «Яндекс.Почты» обнаружили, тем не менее, положительный момент от использования SPDY. Поскольку число соединений с серверами уменьшилось (это ключевая особенность SPDY и HTTP/2), то нагрузка на серверы заметно сократилась).
Методы
С помощью URL, мы определяем точное название хоста, с которым хотим общаться, однако какое действие нам нужно совершить, можно сообщить только с помощью HTTP метода. Конечно же существует несколько видов действий, которые мы можем совершить. В HTTP реализованы самые нужные, подходящие под нужды большинства приложений.
Существующие методы:
GET: получить доступ к существующему ресурсу. В URL перечислена вся необходимая информация, чтобы сервер смог найти и вернуть в качестве ответа искомый ресурс.
POST: используется для создания нового ресурса. POST запрос обычно содержит в себе всю нужную информацию для создания нового ресурса.
PUT: обновить текущий ресурс. PUT запрос содержит обновляемые данные.
DELETE: служит для удаления существующего ресурса.
Данные методы самые популярные и чаще всего используются различными инструментами и фрэймворками. В некоторых случаях, PUT и DELETE запросы отправляются посредством отправки POST, в содержании которого указано действие, которое нужно совершить с ресурсом: создать, обновить или удалить.
Также HTTP поддерживает и другие методы:
HEAD: аналогичен GET. Разница в том, что при данном виде запроса не передаётся сообщение. Сервер получает только заголовки. Используется, к примеру, для того чтобы определить, был ли изменён ресурс.
TRACE: во время передачи запрос проходит через множество точек доступа и прокси серверов, каждый из которых вносит свою информацию: IP, DNS. С помощью данного метода, можно увидеть всю промежуточную информацию.
OPTIONS: используется для определения возможностей сервера, его параметров и конфигурации для конкретного ресурса.
Несколько HTTP соединений
Еще один вариант, как можно увеличить скорость загрузки web-страниц это использовать несколько HTTP соединений. Клиент открывает несколько соединений с web сервер и каждое соединение используется для загрузки разных ресурсов.
Например, первое соединение для загрузки стилевого файла, следующие соединение для загрузки javascript и другие соединения для передачи различных картинок. Каждое такое соединение может быть постоянным и использоваться для загрузки нескольких ресурсов, а также внутри таких соединений можно использовать HTTP pipelining. Почти все современные браузеры используют несколько HTTP соединений как правило от 4 до 8.
Symbols
Недостатки постоянного соединения
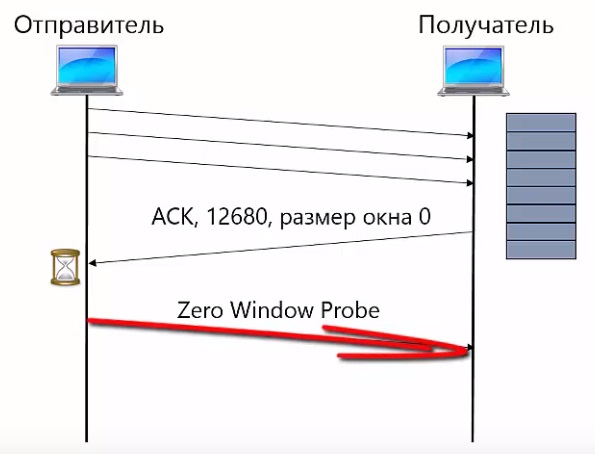
Хотя постоянные HTTP соединение позволяет увеличить скорость передачи данных от web сервера к клиенту, поддержание этого соединения требует ресурсов на сервере. Ресурсы сервера ограничены, и если клиент открыл соединения и его не использует, то этих ресурсов не хватит другим клиентам, особенно это плохо для высоконагруженных серверов, к которым поступают несколько сотен или тысяч запросов в секунду.
Поэтому современные web-серверы автоматически закрывают соединение, если оно не используется в течение какого-то времени, как правило от 5 до 15 или 20 секунд. Обычно этого времени достаточно для того чтобы загрузить web-страницу и все сопутствующие ей ресурсы.
Какими бывают протоколы Интернета
На сегодняшний день известно несколько разновидностей протоколов Интернета. Они имеют следующие обозначения:
- HTTP;
- DNS;
- ICMP;
- FTP;
- UDP;
- TCP/IP — название протокола, являющегося основным для интернет-сетей.
Обратите внимание! Различия между этими решениями кроются в уровнях назначения
И здесь можно разделить решения по нескольким веткам:
- физические уровни. Предполагают, что соединение создаётся при помощи витой пары, оптических волокон;
- ARP-уровень с драйверами устройств;
- сетевой уровень со стандартными ICMP, IP;
- транспортный уровень — UDP и TCP;
- прикладной. Сюда входят стандартные протоколы сети Интернет типа NFS, DNS, FTP, HTTP.
ISO/OSI — система стандартизации, которая используется абсолютно для всех решений. Благодаря этому не возникает сбоев у разнообразных платформ, даже если используются разные операционные системы, оборудование поставляют разные производители. Сейчас такие детали практически не имеют значения.
Обратите внимание! Для функционирования Интернета используется протокол каждого уровня
Обеспечение безопасности
Базовая схема идентификации не предоставляет безопасного метода идентификации пользователя, не обеспечивает она и каких-либо средств защиты объектов, которые передаются открытым текстом по используемым физическим сетям. HTTP не мешает внедрению дополнительных схем идентификации и механизмов шифрования или других мер, улучшающих безопасность системы (например, SSL или одноразовых паролей).
Наиболее серьезным дефектом базового механизма идентификации в HTTP является то, что пароль пользователя передается по сети в незашифрованном виде.
Аутентификация клиентов
Обычным назначением базовой идентификации является создание информационной (справочной) среды, которая требует от пользователя его имени и пароля, например, для сбора точной статистики использования ресурсов сервера. При таком использовании предполагается, что не существует никакой опасности даже в случае неавторизованного доступа к защищенному документу. Это правильно, если сервер генерирует сам имя и пароль пользователя и не позволяет ему выбрать себе пароль самостоятельно. Опасность возникает, когда наивные пользователи часто используют один и тот же пароль, чтобы избежать необходимости внедрения многопарольной системы защиты.
Если сервер позволяет пользователям выбрать их собственный пароль, тогда возникает опасность несанкционированного доступа к документам на сервере и доступа ко всем аккаунтам пользователей, которые выбрали собственные пароли. Если пользователям разрешен выбор собственных паролей, то это означает, что сервер должен держать файлы, содержащие пароли (предположительно в зашифрованном виде). Многие из этих паролей могут принадлежать удаленным пользователям. Собственник или администратор такой системы может помимо своей воли оказаться ответственным за нарушения безопасности сохранения информации.
Передача конфиденциальной информации
Подобно любому общему протоколу передачи данных, HTTP не может регулировать содержимое передаваемых данных, не существует методов определения степени конфиденциальности конкретного фрагмента данных в пределах контекста запроса. Следовательно, приложения должны предоставлять как можно больше контроля провайдеру информации.
Четыре поля заголовка представляют интерес с точки зрения сохранения конфиденциальности: Server, Via, Referer и From.
Раскрытие версии программного обеспечения сервера может привести к большей уязвимости машины сервера к атакам на программы с известными слабостями. Разработчики должны сделать поле заголовка Server конфигурируемой опцией
Прокси, которые служат в качестве сетевого firewall, должны предпринимать специальные предосторожности в отношении передачи информации заголовков, идентифицирующей ЭВМ, за пределы firewall.
Персональная информация
Клиентам HTTP небезразличнен доступ к некоторым данным (например, к имени пользователя, IP-адресу, почтовому адресу, паролю, ключу шифрования и т.д.). Система должна быть тщательно сконструирована, чтобы предотвратить непреднамеренную утечку информации через протокол HTTP. Мы настоятельно рекомендуем, чтобы был создан удобный интерфейс для обеспечения пользователя возможностями управления распространением такой информации.
Преимущества и недостатки протокола
Достоинства
- Интернет протокол HTTP дает возможность достаточно просто создавать нужные клиентские приложения.
- Первоначальные возможности протокола возможно расширить, внедрив свои персональные заголовки.
- Протокол поддерживается как клиент большим числом программ и есть возможность выбирать среди множества хостинговых компаний с серверами HTTP.
Недостатки
- Протокол HTTP не содержит в явном виде возможность навигации внутри ресурсов сервера.
- Отсутствует поддержка распределенности. Промышленное применение интернет протокола HTTP с использованием распределённых вычислений при больших нагрузках на сервер оказывается непригодным.
Заголовки запроса
В запросе клиент должен передать URI запрашиваемого документа. Это может быть сделано в абсолютной или относительной форме. В первом случае в состав URI должны входить название протокола и имя сервера.
Во втором случае передается только путь к документу.
В этом случае имя и порт хоста, может быть передано в строке заголовка Host:
Наличие имени хоста необходимо для обращений к прокси-серверу, или для обращения к одному из виртуальных хостов размещенных на одном сервере. Если хост, заданный одним из двух способов, не существует, то сервер возвращает ответ 400- Bad Request.
Поля заголовка запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте.
Передача данных в ответе сервера
Несколько заголовков используемых в ответе сервера, позволяют точно описать формат и размер передаваемых данных.
Content-Type: Тип сообщения, аналогичен типу содержимого в стандарте MIME и указывается в формате тип/подтип.
Серверы используют типы сообщения в заголовках Content-Type, чтобы сообщить клиенту о том, в каком формате передается прилагаемое содержимое
В типе сообщения для текстовых форматов может быть указана использованная кодировка.
Content-Encoding: Для 8 битового протокола HTTP, данный заголовок означает, что данные дополнительно закодированы, например сжаты. Определены три типа кодирования gzip, compress, deflate, что соответствует форматам программ gzip, compress и библиотеки zlib. Например:
Большое значение в реализации протокола HTTP имеет уведомление клиента о размере данных в теле ответа, т.к. в силу 8 битовости протокола тело ответа не может сопровождаться каким либо ограничителем.
Content-Length: Длина тела сообщения. В протоколе HTTP/1.0 это была единственная возможность передать клиенту информацию о размере данных.
Кодирование данных кусками (chunced) было введено в HTTP/1.1. В заголовках ответа должна присутствовать строка
А тело сообщения строится по следующим правилам
Признаком завершения передачи является кусок нулевой длины.
Следует отметить, что символы в конце куска, не являются его частью.
Подобное кодирование очень удобно в тех случаях, когда размер данных заранее неизвестен, и достаточно велик.
Еще одной возможностью для кодирования данных является использование для тела сообщения типа multipart/bytranges – эквивалентного MIME multipart/*
Если размер сообщения не указан, не используется кодирование кусками и тип тела сообщения не multipart/bytranges, то клиент определяет конец тела ответа по закрытию TCP соединения.
Что такое протокол HTTPS?
Исправить незащищенный протокол HTTP можно с помощью расширения S, которое делает весь пересылаемый массив сведений недоступным для сторонних лиц. Защиту пересылки данных по HTTPS обеспечивает протокол SSL/TLS, кодирующий все сведения.Особенности протокола:
- Шифровка сведений.
- Фиксация изменений в направляемых данных.
- Защита от атак с перехватом – безопасная авторизация пользователя на сервисе.
- Максимальное доверие к сайтам, работающих с HTTPS. Проверка простая – название легко найти в адресной строке.
В ходе формирования соединения через HTTPS создается ключ, известный только компьютеру пользователя и интересуемому серверу. Так зашифровываются все данные. Доступ к ним практически невозможен, т.к. ключ состоит из более 100 символов.
3.1 Content-Type: application/x-www-form-urlencoded.
Пишем запрос, аналогичный нашему запросу GET для передачи логина и пароля, который был рассмотрен в предыдущей главе:
POST http://www.site.ru/news.html HTTP/1.0\r\n
Host: www.site.ru\r\n
Referer: http://www.site.ru/index.html\r\n
Cookie: income=1\r\n
Content-Type: application/x-www-form-urlencoded\r\n
Content-Length: 35\r\n
\r\n
login=Petya%20Vasechkin&password=qq
Здесь мы видим пример использования Content-Type и Content-Length полей заголовка. Content-Length говорит, сколько байт будет занимать область данных, которая отделяется от заголовка еще одним переводом строки \r\n. А вот параметры, которые раньше для запроса GET помещались в Request-URI, теперь находятся в Entity-Body. Видно, что они формируются точно также, просто надо написать их после заголовка. Хочу отметить еще один важный момент, ничто не мешает, одновременно с набором параметров в Entity-Body, помещать параметры с другими именами в Request-URI, например:
POST http://www.site.ru/news.html?type=user HTTP/1.0\r\n
…..
\r\n
login=Petya%20Vasechkin&password=qq
Структура протокола
Каждое HTTP-сообщение состоит из трёх частей, которые передаются в указанном порядке:
- Стартовая строка (Starting line) — определяет тип сообщения;
- Заголовки (Headers) — характеризуют тело сообщения, параметры передачи и другие сведения;
- Тело сообщения (Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
Из этих трёх частей обязательной является стартовая строка, а заголовки и тело сообщения могут отсутствовать. Связано это с тем, что именно стартовая строка указывает на тип запроса/ответа. Исключением является версия 0.9 протокола, у которой сообщение запроса содержит только стартовую строку, а сообщения ответа только тело сообщения.
Методы HTML
Клиент при обращении к серверу в запросе указывает метод, который он хочет использовать.
- Самые популярные методы это GET запрос на передачу веб-страницы, именно этот запрос используются чаще всего.
- POST передача данных на веб-сервер для обработки. Метод post используется например, когда вы пишите комментарии к роликам youtube, остальные методы, кроме get и post используются значительно реже.
- Метод HEAD запрашивает заголовок страницы, то же самое, что и GET только без тела сообщения, хотя HTTP разрабатывался для передачи веб-страниц, создатели HTTP предусмотрели возможность его использования для работы с ресурсами других типов.
- Метод PUT помещение ресурса на веб-сервер.
- Метод DELETE удаление страницы или ресурса с веб-сервера для выполнения этих методов необходимо иметь соответствующие права доступа.
- Метод TRACE позволяет отслеживать, что происходит со страницей, кто вносит в нее какие изменения.
- Метод OPTIONS позволяет узнать, какие именно методы поддерживаются для конкретного ресурса на веб-сервере.
- Метод CONNECT позволяет подключиться к веб-серверу через прокси.
Стандарты (протокола) обмена информацией
Это тоже название определённых правил, по которым передают сведения между участниками Сети в том или ином случае. Передаваемая кодированная информация становится понятной для всех абонентов благодаря применению таких правил. Обычно к ним относят следующие явления:
- приёмы реализации по контролю;
- структура, по которой удалось построить базы данных и т. д.
Обратите внимание! Надёжность передачи информации повышается, если элементы достаточно сложные. Но скорость обработки из-за этого может уменьшаться
Какой протокол является базовым в Интернете — будет рассмотрено далее.
Важно! Практически каждый разработчик может использовать свои собственные решения. Но подобные системы доступны только ограниченному числу пользователей
Интеграция в сложные сетевые процессы обмена информацией становится недоступной.
Поэтому в международной практике используют варианты, которые можно разделить на две крупные ветки. Это уровень обычных компьютерных сетей и промышленные либо полевые линии связи. Понятие используется на практике достаточно давно.
Заключение о протоколе HTTP
Итак, постоянное соединение HTTP позволяет использовать одно и то же TCP соединение для загрузки нескольких ресурсов. Это позволяет сократить время на установку соединения TCP, нет необходимости каждый раз проходить процедуру трехкратного рукопожатия.
В стандарте http 1.0 не было поддержки постоянного соединения, эта возможность была добавлена уже после публикации стандарта в виде заголовка connection: keep-alive. В стандарте http 1.1 все соединения по умолчанию постоянны и заголовок connection: keep-alive использовать не обязательно.
Мы рассмотрели кэширование web и его поддержку в протоколе http. Если в страницу, ввести какой-то ресурс из кэша, то загрузка происходит значительно быстрее, чем если мы обращаемся за тем же самым ресурсом в сеть. Необходимо иметь ввиду, что данные кэшируется не только в кэше web-браузера, это так называемый частный кэш, который является отдельным для каждого пользователя, но и данные могут быть закэшированные в других местах. Например, на прокси-серверах, на обратных прокси-серверах, которые копируют запросы большого количества пользователей и такой кэш называется разделяемый.