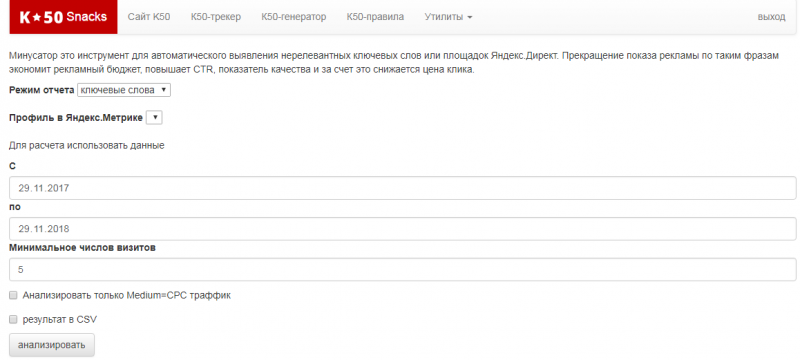
Топ-13 сервисов для сбора ключевых слов и формирования семантического ядра
Содержание:
- Стандартный будильник OS Windows
- Зачем знать частотность запросов
- Что нужно делать.
- Другие возможности Slovoeb по сбору статистики
- Основные возможности Парсера Wordstat
- Как автоматизировать подбор ключевых слов в Вордстате
- Версии навигатора и системные требования для Андроид
- Пошаговая инструкция по работе с Yandex Wordstat
- Основные задачи и причины незаменимости «Яндекс.Вордстата»
- Уточняющий синтаксис в Яндекс Вордстат
- Дополнительные возможности
- 8 лайфхаков для ресторанного SMM
- Программы для анализа плотности слов
- Планировщик ключевых слов Google
- Проработка вглубь
- Инструменты оптимизации
- Используем минус-слова для фильтрации нецелевых запросов
- Что можно делать с помощью SQL запросов
Стандартный будильник OS Windows
Зачем знать частотность запросов
Частотность запросов собирают для прогнозирования трафика. Парсер Wordstat показывает, сколько раз за месяц пользователи вводили в поиске определенную фразу. Эти данные позволяют примерно рассчитать, сколько сайт получит переходов, если займет N-ую позицию в поиске.
Как это работает на практике:
1. Собираете список ключевых фраз. Быстро подобрать ключевики можно с помощью инструмента медиапланирования.
2. Определяете частотность запросов для фразы. Например, «купить Samsung Galaxy в Москве» — 11757 показов в месяц.

3. Узнаете значения CTR в зависимости от позиции в поиске.
Сделать это можно двумя способами:
- Найти данные о распределении CTR в открытых источниках.
- Посмотреть в отчете Яндекс.Вебмастера. Для этого в левом меню выберите «Поисковые запросы» — «Все запросы и группы». Данные отображаются в столбце «CTR на позициях, %».

Последний способ доступен в том случае, если ваш сайт добавлен в Яндекс.Вебмастер и работает хотя бы несколько месяцев.
4. Составляете прогноз трафика для ТОП-10. Для этого умножаете частотность на CTR и делите на 100%.
Например, если CTR на 2-3 позиции составляет 25%, то прогнозный трафик при достижении этой позиции равен: 11757*25/100 = 2939.
Вторая причина анализа частотностей — отсеивание «мусорных» фраз. Это фразы, частотность которых стремится к нулю, и их нет смысла включать на существующие страницы или создавать под них новые страницы.
Но не все ключевые фразы с низкой частотностью являются «мусорными»
Здесь важно учитывать тематику сайта. Если она узкая, то рекомендуется оставлять фразы даже с частотностью 1
Например, по запросу «купить фотоколориметр КФК-3-01» можно получить 1 показ в месяц. Но сайт специализируется на продаже лабораторного оборудования, т.е. относится к сайтам узкой тематики. В таких ситуациях каждый посетитель имеет ценность.

Для магазинов масс-маркета можно отсеивать запросы с частотностью ниже 5. А для информационных сайтов частотность 30-50 вполне может быть нижним пределом. Главное, не переусердствуйте с удалением лишних фраз, иначе есть риск потерять трафик по низкочастотным запросам, который порой составляет до 70-80 % от общего трафика.
Что нужно делать.
Поэтому при сборе семантики, при сборе ключевых слов для Директа, нужно отталкиваться от логики.
Нужно использовать горячие запросы, их тестировать, использовать запросы с указанием точного наименования товара, именно те запросы, которые характеризуют намерения покупатели приобрести или заказать какой-то товар.
Во вторую группу запросов можно определять некие информационные запросы, но здесь уже нужно тестировать и смотреть, будут ли по ним продажи.
Но первую ставку нужно делать именно на горячие запросы. А не раздувать свою рекламную кампанию, чтобы она была непомерно большой.
Другие возможности Slovoeb по сбору статистики
Да, забыл еще упомянуть, что Slovoeb умеет собирать и поисковые подсказки. Это то, что выпадает при вводе запроса в поисковую строку Яндекса или Гугла.
Среди них тоже могут содержаться вполне себе интересные варианты ключевиков, которые потом можно будет проверить описанным чуть выше способом на предмет реальной их частотности.
Раньше для этого существовала отдельная утилита (СловоДер) от того же разработчика (Александра Люстика), а сейчас этот функционал заключен в одной программе. Для сбора поисковых подсказок достаточно нажать соответствующую кнопку на панели инструментов Slovoeb.
В открывшемся окне нужно поставить галочки напротив тех поисковиков, откуда эти подсказки будут дергаться.
Собственно, следует также указать ключевые слова, для которых эти подсказки будут собираться и нажать кнопку «Начать сбор». Собранные ключи из подсказок добавятся к общему списку, чтобы потом можно было их все скопом проверить и собрать статистику частоты использования.
В общем списке они будут помечаться другим значком, чтобы вам было нагляднее с ними работать и различать парсинг Вордстата и поисковых подсказок.
Тоже самое касается и сбора слов из правой колонки Вордстата (Slovoeb умеет ее парсить тоже).
Чуть выше по тексту я говорил, что очень важно при сборке семантического ядра обращать внимание не только на частотность подобранных слов и фраз, но и на то, насколько высокая конкуренция существует в выдаче Яндекса и Гугла по данным запросам. Чем она выше, тем сложнее вам будет пробиться в ТОП
Для ее оценки многие предлагают использовать число ответов поисковых систем, которые они дают на данный запрос. Чуть выше я писал об этом подробнее. Так вот, наша замечательная программа умеет парсить это самое число ответов из выдач Яндекса и Гугла.
Т.е. по всем собранным словам вы сможете пробить их конкурентность с помощью кнопочки KEI на панели инструментов Slovoeb:
Параметр KEI получается несколько утрированным и, чтобы на него опираться, лучше будет воспользоваться Key Collector (платная версия данной бесплатной программы с существенно более расширенным функционалом).
Тем не менее, не у всех есть время и силы на проведения подобной работы (сбор полного семядра), но делать ее все равно нужно обязательно. Однако, если есть спрос, то будет и предложение. Всегда найдутся люди, которые готовы будут проделать это за вас, другое дело, что они могут оказаться не всегда честными и исполнительными.
Позволю себе наглость и приведу в завершении видео, взятое с блога Максима Довженко, где он рассказывает про настройки и подбор слов в Slovoeb:
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Основные возможности Парсера Wordstat
Возможности сервиса:
- Сбор частотности запросов из левой колонки Wordstat для указанных фраз.
- Загрузка фраз списком или с помощью файла XLSX.
- Сбор частотности запросов в любом регионе Яндекса;
- Учет типа соответствия при парсинге (операторы «фраза», «!фраза» и );
- Сохранение всех отчетов «в облаке».
Особенности сервиса:
- Неограниченное количество поисковых запросов при проверке за один раз.
- Не нужно создавать фейковые аккаунты в Яндексе специально для парсинга или рисковать собственными аккаунтами.
- Не нужно использовать прокси-серверы и вводить капчу.
- Суммирование в отчете частотностей по указанным регионам или разбивка по каждому региону.
- Высокая скорость парсинга.
- Удобный для последующей обработки отчет в формате XLSX.
Как автоматизировать подбор ключевых слов в Вордстате
Даже с помощью плагинов вручную работать с Вордстатом достаточно трудоемко. Но процесс можно автоматизировать. Для этого нам пригодится два инструмента Click.ru:
- Подбор слов и медиапланирование.
- Парсер частотностей Вордстат.
Собираем ключевые слова
Зарегистрируйтесь / авторизуйтесь в Click.ru и откройте инструмент «Подбор слов и медиапланирование».
Укажите базовые данные:
- URL сайта, для которого будете собирать слова;
- место размещения рекламы (поиск, контекстно-медийная сеть или оба варианта).
- регионы, в которых планируете показывать рекламу.
По умолчанию система фиксирует стоп-слова (оператор +, который мы рассматривали выше) и проводит кросс-минусацию. Галочки лучше не снимать.
После указания всех необходимых данных нажмите «Начать новый подбор».
Система проанализирует сайт (URL которого указали на этапе базовых настроек). На основе контента сайта система автоматически подберет релевантные ключевые фразы.
Вы можете добавить к этому списку свои слова или воспользоваться дополнительными инструментами автоматического подбора:
- Слова конкурентов. Здесь нужно будет указать URL сайтов-конкурентов. Система проанализирует их и соберет семантику.
- Слова из счетчиков статистики. Откройте доступ к счетчикам Яндекс.Метрики и/или Google Аналитики. На основе их данных система подберет запросы, по которым к вам на сайт приходили посетители.
Автоматический подборщик слов — это хорошо. Но нам нужны данные Вордстата
Обратите внимание на блок «Ручной подбор слов». Это и есть подборщик на основе данных Вордстата
Как работает подборщик:
1. Введите по одному или списком базовые слова:
Система для каждого слова определяет частотность, а также прогнозы по кликам и бюджету в зависимости от желаемой доли трафика (указываете в столбце «Позиция»).
2. Для просмотра вложенных запросов нажмите на значок списка слева от заданной фразы.
Углубляться можно до тех пор, пока не закончатся вложенные запросы.
3. Просмотрите список подобранных слов. Поставьте галочки на тех, которые вам подходят, и нажмите «Добавить в медиаплан». Вы можете отметить одновременно запросы из ручного и автоматического подборщиков, и добавить в общий список.
Система просчитает бюджет по ключевым словам. Отчет со списком выбранных слов можно скачать в XLSX-формате. При желании можете продолжить настройку — в этом случае система сгенерирует объявления под каждое ключевое слово.
Проверяем частотности Вордстат
С помощью парсера Вордстат можно проверить частотность для списка запросов.
Откройте страницу парсера. Укажите список запросов в поле «Список фраз для проверки»
Также фразы можно загрузить с помощью XLSX-файла (обратите внимание, все запросы должны находиться на первом листе файла, 1 ячейка — 1 запрос)
Далее задайте настройки парсера:
- широкое соответствие;
- оператор «» (фиксирует количество слов в фразе);
- оператор «кавычки» с восклицательным знаком. Фиксирует количество слов в фразе и словоформу каждого слова;
- оператор [] (квадратные скобки). Используется для фиксации порядка слов в фразе.
Поставьте галочки на нужных параметрах (можете проставить галочки на всех четырех). Затем жмите «Запустить проверку». В течение нескольких минут отчет будет готов, и его можно будет скачать в разделе «Список задач».
Отчет скачивается в формате XLSX-файла. Для каждого запроса в таблице указана частотность. Данные по частотности с учетом операторов поиска указаны в отдельных столбцах. Отфильтруйте список и удалите фразы с околонулевой частотностью.
Вот подробный гайд по работе с парсером Вордстат.
Версии навигатора и системные требования для Андроид
Пошаговая инструкция по работе с Yandex Wordstat
Для грамотного использования Яндекс Вордстат необходимо:
- Зарегистрироваться и войти в свою почту (аккаунт) на Яндексе;
- Записать в поле запрос и кликнуть «Подобрать».
Если вы не залогинились в своем аккаунте, то Yandex Wordstat при заходе в него предложит вам сделать это.
Давайте пробежимся по функционалу интерфейса.
Под основной строкой для ввода ключевого слова есть три флажка:
- «По словам»;
- «По регионам»;
- «История запросов».
Подробнее работу с каждым из них мы рассмотрим далее.
Справа ссылка «Все регионы» — позволит выбрать и посмотреть статистику ключевика по заданному региону.
Сбор запросов по словам
Как видно из вышеприведенного скриншота в Яндекс Вордстат этот вариант стоит «по умолчанию». Он показывает статистику запросов по региону, если тот выбран, если нет, то статистика показывается по всем регионам.
Давайте введем в основное поле фразу «Стройматериалы» и посмотрим, что покажет нам Wordstat. Возможно, вам придется ввести капчу. У меня обошлось без этого.
Система выдаст две колонки, которые будут содержать различные вариации заданного ключевого слова.
В левом столбце Яндекс Вордстат будут все прямые и непрямые вхождения. Правый — отобразит похожие запросы — «стройматериалы», «строительные материалы», «строительный рынок» и т.д. Т.е. отсюда можно выбрать достаточно интересные ключи для продвижения и этим не стоит пренебрегать.
Цифры, расположенные справа от запросов — это количество показов в месяц. Но это всего лишь прогнозируемый Яндексом результат, который вычисляется из статистики поисковика. Т.е. реальный результат может быть больше или меньше прогнозируемого. Но в принципе, плюс/минус Яша всегда показывает «правду».
Еще можно посмотреть статистику отдельно для десктопов, мобильников и т.п., просто переключив флажок в соответствующее поле, под основным полем ввода исследуемой фразы.
Сбор ключевых слов по регионам
При просмотре ключей по регионам на выбор предлагается 3 вкладки:
- Регионы;
- Города;
- Все вместе.
Справа, напротив каждого запроса мы видим соотношение популярности ключа к тому или иному региону. Если кликнуть на соответствующую ссылку, то можно отсортировать запросы по региональной популярности.
Можно посмотреть частотности ключевых слов, показываемые на том или ином устройстве: смартфоне, планшете, ПК и т.д.
Кликнув по вкладке «Карта» откроется интерактивная карта. Наведя мышку на интересующую область, отобразится статистика по этому региону. Желтые области на карте относятся к наиболее популярным, красные к менее популярным.
Как посмотреть историю запросов
Установив флажок в поле «История запросов» можно посмотреть частоту показа этого запроса в определенный период времени (неделя, месяц, год). Таким образом определяются сезонные фразы.
Что это значит? Сезонные запросы – это те запросы, которые пользователи вбивают только в определенное время. Например, фраза «купить велосипед» будет вводиться в поиске Яндекса гораздо чаще весной и летом, чем осенью и зимой. Думаю, что вы со мной согласитесь.
График показывает наглядное изменение количества вводимых фраз за период с 2018 года по 2019. Здесь же можно сделать группировку по неделям и месяцам и выбрать требуемое устройство, как и на предыдущей вкладке.
На графике показаны две кривые – с абсолютным и относительным значениями. Абсолютное показывает значение в данный момент, а относительное – отношение реального количества к общему числу показов за неделю или за месяц. Это общая популярность фразы.
Специальные операторы
Например, вам надо, чтобы сервис показал только определенные фразы в точной словоформе, падеже, числе и тому подобное. Для этого надо обрамить фразу в кавычки и поставить перед каждым словом восклицательный знак. Например, «!жилье !за !границей».
| Оператор | Значение |
| — | Если фраза содержит знак минус, то это слово удаляется. |
|
+ |
Если фраза содержит знак плюс, то показываются только те запросы, которые содержат это слово. |
|
«» |
Фраза в кавычках показывает все слова из данного запросов в любом порядке и словоформе. |
| «!» | Точное вхождение. |
Например, если мы ищем «жилье за -границей», то нам будут показаны только фразы с «жилье за». Слово «граница» не будет учитываться.
Основные задачи и причины незаменимости «Яндекс.Вордстата»
«Я.Вордстат» – это онлайн-сервис «Яндекса», который открывает свободный доступ к важным статистическим данным поисковой системы. С его помощью можно узнать о том, что, как и когда ищут пользователи. Чтобы получить доступ к инструменту, достаточно иметь обычный пользовательский аккаунт в «Яндексе». Если профиль уже есть, то можно сразу переходить на wordstat.yandex.ru и начинать пользоваться инструментом.
Сервис дает возможность выяснить:
- популярность определенных поисковых запросов;
- сезонность спроса;
- спрос в разных регионах;
- тип устройства и платформы входа пользователей;
- актуальные тренды.
Для каждого интернет-маркетолога такие данные – это большая ценность. По сути, поисковая система собрала и систематизировала статистику по вашей целевой аудитории и предлагает эту информацию совершенно бесплатно. С ее помощью можно формировать стратегию продвижения с высокой вероятностью на успешность ее практического внедрения. Бизнесу не придется «играть вслепую», надеясь, что именно эта информация покажет результат. Приведем простой пример из ниши строительного инструмента.
Вот история спроса по запросу «аналоговый уровень»:
История спроса по запросу «Аналоговый уровень»
Запрос «Аналоговый уровень»
А это аналогичный показатель по запросу «цифровой уровень»:
История спроса по запросу «Цифровой уровень»
Запрос «Цифровой уровень»
Что мы видим? Однозначно можно сказать, что цифровыми инструментами интересуются практически в 3 раза чаще, что делает эту товарную нишу более перспективной для бизнеса. При этом наблюдается сезонный пик, который логично совпадает с весной, то есть периодом, когда все мастера запасаются инструментом.
Уточняющий синтаксис в Яндекс Вордстат
Давайте снова взглянем на скришот, показывающий статистику по запросу «ключевое слово». На нем мы видим, что данная фраза упоминалась пользователями в поисковике более 62 тысяч раз в течение месяца.
И, кажется, что попадание в ТОП-1 поиска по ней принесет сайту минимум 15-20 тысяч ежемесячного трафика. Забегая вперед, скажу, что в реальной жизни сайт, занимающий первую позицию в поиске по данному запросу, получает по нему не более 200 посетителей – разница в 100 раз это не шутка.
Представьте, что вы вложили в продвижение своего проекта 100 тысяч, рассчитывая, что заработаете 200, а покупателей оказалось в 100 раз меньше и вы заработали 2 тысячи – это провал всего бизнес плана.
Может показаться, что статистика запросов от Яндекс врет и надо искать другой инструмент. Но не спешите, надо просто научиться правильно пользоваться вордстатом.
Есть такая штука – синтаксис поисковых запросов – это когда добавление специальных символов позволяет задавать поисковой системе более точные критерии поиска. Синтаксис запросов работает как в обычном поиске, так и в Yandex Wordstat – давайте учиться его использовать.
1. Исключаем всё лишнее (кавычки)
Первая причина завышенных результатов в статистике запросов – это учет не только той фразы, которую вы ввели в строке сервиса, но и всех фраз в которые она входит.
Обратите внимание, что в примере выше мы видим цифры не только запроса «ключевое слово», но и «ключевые слова яндекс», «статистика ключевых слов» и т.д. Весть этот список суммируется
Но, если мы возьмем наш запрос в кавычки, то все приставки и хвостики в учет не пойдут. Получится вот так:
Теперь мы видим, что цифра в 62 тысячи запросов уменьшилась до 1906 – это существенно ближе к истине, но еще не идеал.
2. Избавляемся от словоформ (восклицательный знак)
Запросы «ключевое слово», «ключевые слова», «ключевом слове» и т.д. мы считаем разными, но поисковая система, по-умолчанию, считает их одним и тем же, что опять размывает статистические данные.
Для того, чтобы исключить из месячных показов ненужные словоформы достаточно поставить перед каждым словом из запроса восклицательный знак, как в примере ниже:
Теперь мы видим всего 411 запросов, но это те самые случаи, когда пользователь ввел только выбранные слова в нужных падежах и склонениях.
3. Соблюдение порядка слов (квадратные скобки)
Еще одна не очевидная фишка поисковика – это безразличие к порядку слов во фразе. Для Яндекс Вордстат запрос «ключевое слово» и «слово ключевое» – одно и то же. В данной фразе этот момент не критичен, но есть запросы, где от порядка слов многое зависит.
За сохранение порядка слов отвечает оператор квадратные скобки ([]).
Такой формат можно считать эталонным.
4. Учет предлогов в статистике (плюс слова)
Следующая особенность поисковых систем – они не учитывают в статистике предлоги. Считается, что эти слова не несут смысловой нагрузки и ими можно пренебречь.
Для учета предлогов придется использовать дополнительный оператор – это знак плюс.
Используя «+» вы можете включать в учет нужные предлоги и отбрасывать фразы их не содержащие. Пишется вот так:
5. Исключение из учета отдельных слов (минус слова)
Нередко возникает необходимость получить общую статистику по фразе, не уточняя её кавычками, но без учета определенных добавок. Например, продавая какую-то услугу, нам необходимо вычислить спрос на нее. Естественно, существуют люди, желающие получить ее бесплатно – их в расчет брать не желательно.
Исключить слово «бесплатно» мы можем оператором «минус». Впрочем, минус удаляет из статистики любое слов стоящее за ним, не только «бесплатно».
Вот как используется данный синтаксис:
Одновременно можно использовать любое количество минус слов, разделяя их пробелами и ставя перед каждым знак “-“.
6. Объединение статистики по схожим запросам
Существует в Вордстате возможность не только уточнять запросы, но и наоборот – объединять данные по схожим фразам.
Как это работает: Допустим, у вас есть 4 ключа, по которым планируется продвижение страницы – это «яндекс вордстат», «yandex wordstat», «яндекс wordstat» и «yandex вордстат».
Мы можем взять общую статистику по всем 4 запросам. Для этого используем круглые скобки и вертикальную черту (прямой слэш). Внутри скобок слэшем разделяем варианты.
Пример: (слово1|слово2) одинаковая часть
Блоков с круглыми скобками может быть несколько, а общая часть может вовсе отсутствовать, как в на скриншоте ниже:
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
8 лайфхаков для ресторанного SMM
Программы для анализа плотности слов
Кроме он-лайн сервисов для анализа контента на сайте, существуют программы, выполняющие подобные функции. Наиболее известными из них являются:
- Semonitor – мощная программа для решения SEO-задач. В этой программе есть html-анализатор, именно он позволяет проверить плотность ключевых слов на страницах сайта. Программа является платной, цена зависит от версии и количества компонентов. Демо-версию можно скачать на сайте semonitor.ru
- CS Yazzle – программа позволяет собирать внешние ссылки на сайт, анализировать уровень конкуренции по запросам и выполнять ряд других функций, в том числе — выполнять проверку частотности слов на странице. Программа платная, скачать ее можно с сайта yazzle.ru
Мы описали наиболее популярные сервисы для проверки плотности ключевых слов. Формулы расчета плотности у разных сервисов отличаются, как и получаемые результаты. По какой методике считать плотность, учитывать или нет стоп-слова, считать плотность каждой словоформы в отдельности или нет – каждый SEO специалист должен решить сам.
Планировщик ключевых слов Google
Для создания эффективного рекламного объявления очень важно подобрать ключевые слова, которые привлекут внимание целевой аудитории. Компанией Google реализован простой инструмент создания рекламных кампаний в поисковой сети – эффективный планировщик ключевых слов
Возможности планировщика ключевых слов Google:
- Подбор ключевых слов и словосочетаний для определения наиболее подходящих вариантов;
- Оценка предполагаемой эффективности перечня ключевых слов;
- Определение бюджета рекламной кампании на базе расчётных ставок для каждого ключевого слова;
- Формирование рекламного плана;
- Формирование статистики по трафику, а также прогнозов по трафику.
Стоимость: сервис бесплатный.
Проработка вглубь
Вот мы и собрали весь список возможных дополнений к нашим базовым ключам, что же делать дальше? А дальше нужно подготовить список ключевых фраз для еще большей проработки вглубь — поиска запросов со всеми возможными уточнениями.
Необходимо по очереди скомпоновать между собой ключи из разных столбцов, «перемножить» их друг с другом, получив все возможные комбинации. В решении этого вопроса помогут специальные программы, например, генератор фраз PPC-help. Вставляем наши ключи из столбцов таблицы Excel и получаем готовый список ключевых фраз, которые позже мы используем для парсинга в KeyCollector:
Генерация фраз в программе PPC-help
Таким образом, мы собрали семантическое ядро для дальнейшего парсинга. Потратьте еще немного времени и проверьте весь список ключевых фраз. Все ли они соответствуют вашей тематике? Все ли они описывают ваши услуги или продукты? Если есть лишние, удалите их, это сэкономит много времени в будущем.
Список готов? Приступайте к парсингу в Key Collector. Это незаменимый инструмент в работе специалиста по контекстной рекламе. Он значительно упрощает процесс создания семантического ядра, собирая запросы на основе загруженных масок ключевых фраз.
Запускайте программу, загружайте ключи, не забудьте выбрать целевой регион и ждите результатов. Помните, что после получения списка из Key Collector необходимо избавиться от дублей типа «доставка цветы москва» и «москва цветы доставка», чтобы в дальнейшем исключить конкуренцию внутри кампании. Также нужно удалить нецелевые запросы, по которым мы не хотим рекламироваться, сохранив при этом список минус-слов в отдельный файл
В финале важно провести кластеризацию, разбив фразы на тематические группы. Все это удобно делать прямо в Key Collector
Как видим, сбор семантического ядра является трудоемким и затратным по времени процессом, но важным этапом создания кампании, поскольку от качества семантики напрямую зависит успешность рекламы, а значит, и финансовая отдача.
Удачных вам рекламных кампаний!
Инструменты оптимизации
Оценка популярности поисковых систем определяется по их доле трафика. Статистика рейтингов на первые пять месяцев 2017 года:
Поисковые системы отличаются друг от друга. Поэтому для лучшего продвижения сайта желательно сосредоточиться на какой-то одной. При оценке качества сайта Яндекс статистика рассматривает более 150 различных факторов, постоянно меняя и совершенствуя механизм поиска.
Штрафные фильтры сильно затрудняют действия серым, оранжевым и черным оптимизаторам. Поисковая статистика Яндекса рекомендует использовать только белую оптимизацию для достижения успеха. Она начинается с технических параметров. Для улучшения необходимо сделать:
- код ответа сервера 200 для конкретной страницы;
- кроссбраузерность сайта (одинаковое отображение в различных браузерах);
- оптимизацию под операционные системы для мобильных устройств;
- минимальное время загрузки сайта (до 2 секунд);
- доступность редактирования метатегов страниц;
- надежный хостинг;
- отсутствие ссылок на несуществующие страницы.
Статистика Яндекса советует выстроить навигационную конфигурацию сайта для правильной работы поискового робота. Поэтому желательно:
- расположить страницы строго по разделам и категориям;
- создать карту сайта при наличии большого количества страниц;
- присвоить уникальный адрес каждой странице;
- использовать robots.txt для закрытия ненужных страниц;
- удалить дублирующую информацию.
Простого набора ключей недостаточно для продвижения сайта. Информация должна удобно подаваться заинтересованным клиентам, причем ее суть необходимо раскрыть на первой странице и понятным языком. У посетителей сайта не должно возникать вопросов типа: как правильно пользоваться видео. При больших размерах текста разбивка на отдельные страницы облегчит работу Яндекс поиску.
Статистика поисковых запросов Яндекс отмечает, что строка поиска «видит» около 65 знаков. Поэтому длинные заголовки теряют смысл.
Статистика ключевых слов на Яндексе рекомендует использовать их в заголовках. Однако следует помнить, что заголовок из набора ключевых слов неприемлем. Сниппет (фрагмент текста для поисковых систем) желательно делать не более 60 знаков, а description до 150–170 символов.
Статистика запросов Яндекс также использует региональные факторы. Поэтому при прочих равных условиях web-ресурс местного региона будет в приоритете. Следовательно, не обойтись без указания адреса организации и регистрации в Яндекс Справочнике.
Оптимизируя под Яндекс браузер изображения не надо заменять графикой текст, т. к. робот не может определять по ним содержание страницы. Одним из главных требований к сайту является его безопасность. При обнаружении на странице вирусов статистика Яндекса фиксирует понижение их рейтинга. Для СЕО-оптимизаторов разработаны следующие инструменты:
- Яндекс Вебмастер.
- Яндекс Метрика.
- Яндекс Директ.
- Вордстат Яндекс (Wordstat Yandex).
Используем минус-слова для фильтрации нецелевых запросов
При проверке фразы в Вордстате сервис покажет поисковые запросы, которые могут содержать нерелевантные слова. Такие слова желательно исключить, чтобы оценить чистый спрос на вашу услугу или товар.
Эту фразу пользователи ищут примерно 690 тысяч раз в месяц. При этом запросы с этой фразой иногда содержат слово «недорогой».
Если такой запрос для нас является нецелевым (например, вы продаете только геймерские ноутбуки с топовой начинкой), его лучше исключить из статистики.
Для этого используем минус-слова. Вводим в поисковую строку Вордстата запрос «купить ноутбук» и добавляем минус-слово «-недорогой». Жмем «Подобрать» и видим: количество запросов стало меньше, а в блоке «Что искали со словом» — нет результатов, содержащих слово «недорогой».
Также к основной фразе можно добавить несколько минус-слов, чтобы исключить другие нерелевантные запросы. Посмотрите запросы из левой и правой колонок, найдите слова или фразы, которые вам не подходят, и укажите их в качестве минус-слов.
На выходе вы получите чистые данные по релевантным запросам, что поможет качественно оценить спрос.
Какие группы слов часто используют в качестве минус-слов в контекстной рекламе:
- DIY-слова — «сделать», «своими руками», «самостоятельно» и т. д.;
- маркеры информационных запросов («почему», «как», «чем», «какой» и т. п.);
- слова «мусорного» спроса — «бесплатно», «giveaway», «в дар» и т. п.
- маркеры вторичного рынка — «бу», «подержанный»;
- характеристики или свойства продукта, которые не подходят для вашей кампании. Например, если вы продаете только мужские кроссовки, исключите из статистики слова «женские» и «детские».
Операторы поиска: уточняем статистику по запросам
С помощью операторов поиска можно уточнить запрос и посмотреть точную статистику показов по фразе в нужной форме или с определенным порядком слов. Использование операторов доступно в разделах «По словам» и «По регионам».
Кавычки » » (фиксация слов)
При указании запроса в кавычках вы увидите статистику только по указанному словосочетанию (без добавления других слов). При этом порядок слов и окончания могут меняться.
Восклицательный знак! (фиксация словоформы)
Используется для фиксации окончания в указанном виде и размещается перед словом, в котором его нужно зафиксировать.
Обратите внимание! Используйте оператор «кавычки» совместно с оператором «!». Так вы сможете узнать точную частотность любого запроса
Плюс + (фиксация стоп-слов)
Используется для проверки частотности по запросам, содержащим стоп-слова (служебные части речи, местоимения и др.). По умолчанию в Яндекс.Вордстате они не учитываются. Например, если мы введем в Вордстате фразу «двери для», сервис покажет статистику без учета предлога «для».
Сравните сами. По запросу «двери» сервис показывает 9 631 111 показов в месяц:
А вот статистика по запросу «двери для» (результат аналогичный):
А теперь фиксируем стоп-слово «для» и получаем уже 831 973 показов в месяц, а не 9 631 111.
Вертикальный слэш | (логический оператор «или»)
Применяется для объединения статистики по разным запросам. Например, если мы продаем входные двери, полезно узнать количество запросов от владельцев квартир и загородных домов. Для этого используем оператор | — вводим в Вордстате такую фразу:
В результатах подбора будет статистика по запросам, содержащим любое из словосочетаний, указанных в круглых скобках.
Квадратные скобки [] (фиксация порядка слов)
При использовании этого оператора система покажет статистику по запросам, в которых содержатся указанные слова в заданном порядке.
Использование [] поможет исключить запросы с иным порядком слов и зафиксировать нужный порядок слов
Это важно, например, если вы рекламируете продажу билетов по конкретным направлениям