Алгоритм подбора ключевых слов в яндекс.директе
Содержание:
- Поиск минус-слов при анализе рекламной кампании
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Ответы на вопросы, хитрости при работе с «Вордстатом»
- Версии навигатора и системные требования для Андроид
- Ваше предложение:
- Ответы на распространенные и неочевидные вопросы по теме
- Еще раз про НЧ запросы
- Что отсекать сразу
- Очистка СЯ от «мусора»
- Можно ли стерилизовать банки в микроволновке
- Уточняющий синтаксис в Яндекс Вордстат
- Key Collector и СловоЕБ
- Приложения
- КМС Google
Поиск минус-слов при анализе рекламной кампании
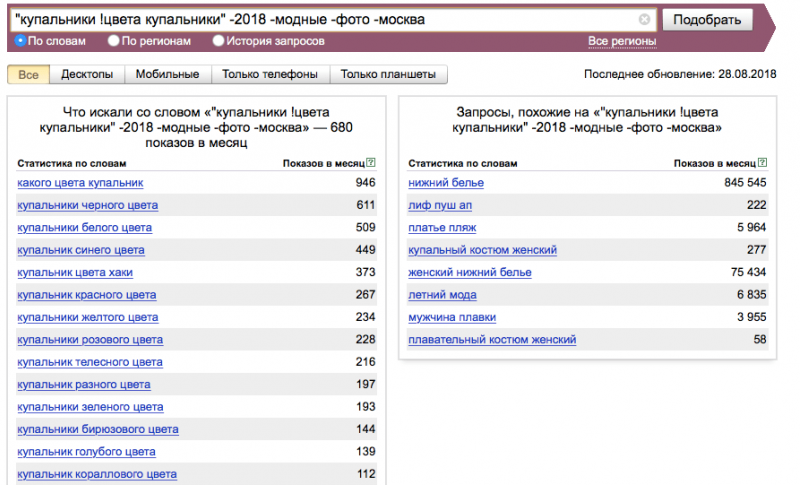
Выявлять минус-слова можно и нужно в процессе анализа рекламной кампании. Для этого мониторьте запросы с высоким показателем отказов.
В Яндекс.Директе – в отчете по поисковым запросам:
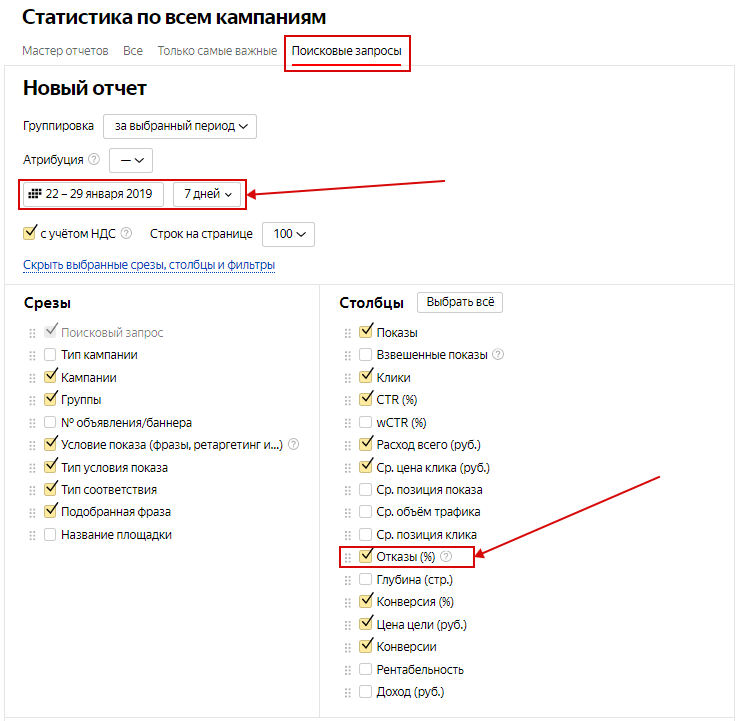
В Google Рекламе похожий отчет ищите здесь:
Отказов по запросу больше 50%? Смело добавляйте в минус-список.
Чтобы ускорить и упростить сбор минус-слов в этом случае поможет расширение для Chrome – Negative Keywords tool. С помощью него вы можете добавлять нецелевые запросы в список минус-слов в пару кликов, как и в Wordstater, но уже не из Вордстата, а из отчета по поисковым запросам.
Если у вас настроен счетчик Яндекс.Метрики, вам пригодится утилита К50 для минусации запросов.
Вход по логину и паролю:
Задаете следующие настройки – и сервис выявляет нерелевантные ключи (и площадки) на основе данных из Яндекс.Метрики:

На выходе получаете список слов по возрастанию релевантности.
Высоких вам конверсий!
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:

Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/

Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:

Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».

Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:

Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:

Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:

Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:

И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:

Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Ответы на вопросы, хитрости при работе с «Вордстатом»
За годы работы с «Вордстатом» у меня накопилась небольшая методичка по ответам на часто задаваемые неочевидные вопросы. Думаю, вы найдете что-то полезное.
Собрали кучу данных
Как проводить анализ запросов? На что обращать внимание?. В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее
Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее. Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
Чем больше расхождение в цифрах, тем больше у вас шанс не угадать намерение пользователя. Например, запрос «боковое стекло хендай» плохой, потому вообще непонятно, что ищут. Дефлектор бокового стекла? Само стекло? Левое? Правое? Переднее? Купить или продать?
Пример хорошего запроса:
2. Как посмотреть статистику запросов для одного города?
Выберите свой город в настройках региона. Помимо города хорошо бы понимать целевую аудиторию и дополнительно затачивать сайт под целевую аудиторию. Например, эвакуатор или вскрытие дверей почти наверняка будут искать со смартфона или планшета.
3. Как обойти ограничение на длину запроса в 8 слов?
Через «Вордстат» такие данные собрать нельзя. Запросы из 8 и более слов можно собрать в поисковых подсказках, найти в различных базах запросов или получить в статистике своего сайта.
4. Что означают абсолютные и относительные данные в истории запросов?
Абсолютный показатель – это фактическое цифровое значение, сколько было таких запросов за период. Относительное значение показывает популярность запроса среди всех запросов в поиске.
5. Что делать, если «Вордстат» собрал 2000 запросов, но нужно больше?
В широких нишах на 40-й странице «Вордстата» только начинается самое интересное:
Если в «Вордстат» ввести запрос в кавычках, повторяя основное слово, вы увидите все запросы из Х слов, содержащих нужное слово. Х – количество слов во фразе в кавычках. Пример:
Используя поочередно конструкции:
- «налог налог налог налог налог налог налог»
- «налог налог налог налог налог налог»
- «налог налог налог налог налог»
- «налог налог налог налог»
- «налог налог налог»
- «налог налог»
- налог
Можно собрать все запросы, которые содержат слово «налог» или его склонения.
6. Как провести массовую проверку частотности запросов из «Вордстат»?
Массово проверить все частотности фраз можно сделать в «Кей Коллекторе» или его бесплатном аналоге – программе «Словоеб».
7. Как убрать капчу в «Вордстате»?
Причина появления капчи – большое количество запросов с 1 IP адреса. Вы можете или сменить айпишник, или использовать программы для работы с «Вордстатом» вместе с сервисами разгадывания капчи.
8. Почему у «Вордстата» ограничение длины в 7 слов?
«Вордстат» изначально был создан как сервис статистики для «Яндекс Директа», в котором максимальное количество слов в рекламной фразе – 7. Никаких других причин для ограничения запроса нет.
Источник статьи
Версии навигатора и системные требования для Андроид
Ваше предложение:
Ответы на распространенные и неочевидные вопросы по теме
- Мы собрали внушительный массив информации. Что теперь делать? Как анализировать?
Сначала нужно отделить коммерческие запросы, спрос которых в кавычках и без них отличается не более чем на 100 %. Оптимизация под такие запросы быстро дает хорошие результаты, особенно если в нише нет активной конкуренции. Чем больше будет «пропасть» между частотностями, тем больше шансов не угадать потребности пользователя поисковой системы. К примеру, плохой запрос – это «колесо велосипеда». Такая формулировка не дает возможности понять, что ищет человек. Может, ему нужна покрышка для колеса или спицы? Колесо интересует переднее или заднее? Он хочет продать, купить или отремонтировать? Непонятно.
- Как получить данные по запросам в разрезе одного населенного пункта?
Для этого нужно выбрать целевой город в расширенных настройках региона
Важно помнить, что географический фильтр – это не самая важная настройка. Обязательно нужно анализировать запросы с учетом платформы пользователя
К примеру, доставку еды, такси, эвакуатор и подобные услуги чаще всего заказывают с помощью мобильного телефона. Поэтому локальному бизнесу стоит одновременно использовать фильтры по региону и по устройству входа.
- Можно ли анализировать запросы более 8 слов?
К сожалению, своим пользователям Yandex Wordstat такой возможности не предоставляет. Но информацию можно получить с помощью поисковых подсказок, внутренней статистики своего сайта и специальных баз данных.
- Что означает цветовая индикация «Абсолютное» и «Относительное» в анализе истории запросов?
Мы уверены, что многие читатели еще в начале статьи обратили внимание на то, что графики имеют разный цвет и это точно неслучайно. Понятия «Абсолютное» и «Относительное» в истории запросов
Цветовая индикация «Абсолютное» и «Относительное»
Понятия «Абсолютное» и «Относительное» в истории запросов
Цветовая индикация «Абсолютное» и «Относительное»
Синий график демонстрирует абсолютный показатель, то есть реальное число запросов за выбранный период. Красным цветом маркируется график, который показывает популярность запроса по отношению ко всем другим, полученным системой.
Еще раз про НЧ запросы
И какая еще есть дилемма те, кто не располагает большим бюджетом для настройки Директа, они начинают искать больше низкочастотных запросов, это такое направление у людей в голове, они начинают создавать кампании под тысячу запросов.
Здесь минус какой: вот создали вы кампанию с тысячью запросов. За ними очень сложно следить, то есть это аналитика такой кампании – это просто ужас. Если у вас в кампании 150 слов, их проанализировать очень легко.
Также практика говорит о том, что продажи приносят несколько процентов запросов. Там если из 100% взять, 5% запросов реально приносят продажи, остальные просто жрут деньги. поэтому смысла нашпиговывать свою кампанию НЧ-запросами вообще никого нет.
Потому что надо помнить эту аксиому, что количество кликов по рекламному объявлению не равно количеству заявок.
Это абсолютно разные понятия. Количество кликов будут характеризовать качество рекламы, но кликают люди разные. Главное, чтобы кликали те, кто заинтересован в покупке.
Это главный принцип подбора ключевых слов при настройке Яндекс Директа.
Потому что большое количество рекламодателей начинает использовать большое количество НЧ-запросов в своих рекламных кампаниях как раз те, у которых маленький бюджет.
И получается, поэтому НЧ-запросу, по которому 9 показов в месяц, у него конкуренция – аж 200 рекламодателей его используют. Естественно цена за клик за такой запрос, может даже 100 рублей стоить.
Что отсекать сразу
Во-первых, все информационные запросы – на поиске они только сливают бюджет. К ним относятся все фразы со словами «фото / видео», «своими руками», «инструкция», «скачать», «как» и т.д.
Во-вторых, запросы, выдача по которым не призывает к продаже / заказам. То, что мы рассматривали в параграфе выше.Те же информационные запросы, замаскированные под коммерческие.
Тут всё очевидно, чисто информационный интерес со стороны пользователей. А есть неочевидные вещи – рассмотрим их на конкретных примерах.
Пример 1: пользователь ищет инструкцию по тому, как сделать самостоятельно, а не готовую услугу
Проект наших клиентов – регистрация юридических лиц. По фразе «Регистрация ООО» конверсий была уйма, по «Зарегистрировать ООО» – ни одной. Дело в том, что во втором случае люди хотят решить свою задачу самостоятельно, а не платить кому-то деньги.
Бывает и наоборот.
Пример 2: пользователь ищет готовую услугу под ключ, а не товар, чтобы его купить и самостоятельно доводить до ума
Актуально для автотематики. Поясним на примере по продаже усиленны пружин для авто с доставкой по нескольким регионам. Есть фраза «Пружина усиленная Kia Cerato», а есть – «Усилить пружины Kia Cerato».
Казалось бы, практически одинаковые запросы, но разница в формулировке решает всё. В нашем примере пружины продаются с доставкой, поэтому трафик по запросам со словом «Усилить» – мимо кассы. Бизнес-процессы продавца не заточены под это.
Пример 3: вы предлагаете что-то конкретное по слишком широким запросам, под которые попадают несколько товаров / услуг / технологий.
Например, продавец входных шумоизоляционных дверей рекламируется по ключевикам типа «Звукоизоляция квартиры».
В чем подвох? Клиентам не нужны двери. Под звукоизоляцией квартиры они понимают стены / потолок.
Очистка СЯ от «мусора»
Покажем, как это делать в Key Collector.
Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации:
Задаем условие, как указано на скриншоте, и пишем слова:
Отмечаем фразы и добавляем в корзину:
Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
Стоп-слова (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.)
Нажимаем этот значок в верхнем меню:
В окне настроек добавляем фразы (1) и разбиваем по группам (2):
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:
Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:
Далее — требования по частоте:
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись. Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе. Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу. Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка». Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную. Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
Можно ли стерилизовать банки в микроволновке
Уточняющий синтаксис в Яндекс Вордстат
Давайте снова взглянем на скришот, показывающий статистику по запросу «ключевое слово». На нем мы видим, что данная фраза упоминалась пользователями в поисковике более 62 тысяч раз в течение месяца.
И, кажется, что попадание в ТОП-1 поиска по ней принесет сайту минимум 15-20 тысяч ежемесячного трафика. Забегая вперед, скажу, что в реальной жизни сайт, занимающий первую позицию в поиске по данному запросу, получает по нему не более 200 посетителей – разница в 100 раз это не шутка.
Представьте, что вы вложили в продвижение своего проекта 100 тысяч, рассчитывая, что заработаете 200, а покупателей оказалось в 100 раз меньше и вы заработали 2 тысячи – это провал всего бизнес плана.
Может показаться, что статистика запросов от Яндекс врет и надо искать другой инструмент. Но не спешите, надо просто научиться правильно пользоваться вордстатом.
Есть такая штука – синтаксис поисковых запросов – это когда добавление специальных символов позволяет задавать поисковой системе более точные критерии поиска. Синтаксис запросов работает как в обычном поиске, так и в Yandex Wordstat – давайте учиться его использовать.
1. Исключаем всё лишнее (кавычки)
Первая причина завышенных результатов в статистике запросов – это учет не только той фразы, которую вы ввели в строке сервиса, но и всех фраз в которые она входит.
Обратите внимание, что в примере выше мы видим цифры не только запроса «ключевое слово», но и «ключевые слова яндекс», «статистика ключевых слов» и т.д. Весть этот список суммируется
Но, если мы возьмем наш запрос в кавычки, то все приставки и хвостики в учет не пойдут. Получится вот так:
Теперь мы видим, что цифра в 62 тысячи запросов уменьшилась до 1906 – это существенно ближе к истине, но еще не идеал.
2. Избавляемся от словоформ (восклицательный знак)
Запросы «ключевое слово», «ключевые слова», «ключевом слове» и т.д. мы считаем разными, но поисковая система, по-умолчанию, считает их одним и тем же, что опять размывает статистические данные.
Для того, чтобы исключить из месячных показов ненужные словоформы достаточно поставить перед каждым словом из запроса восклицательный знак, как в примере ниже:
Теперь мы видим всего 411 запросов, но это те самые случаи, когда пользователь ввел только выбранные слова в нужных падежах и склонениях.
3. Соблюдение порядка слов (квадратные скобки)
Еще одна не очевидная фишка поисковика – это безразличие к порядку слов во фразе. Для Яндекс Вордстат запрос «ключевое слово» и «слово ключевое» – одно и то же. В данной фразе этот момент не критичен, но есть запросы, где от порядка слов многое зависит.
За сохранение порядка слов отвечает оператор квадратные скобки ([]).
Такой формат можно считать эталонным.
4. Учет предлогов в статистике (плюс слова)
Следующая особенность поисковых систем – они не учитывают в статистике предлоги. Считается, что эти слова не несут смысловой нагрузки и ими можно пренебречь.
Для учета предлогов придется использовать дополнительный оператор – это знак плюс.
Используя «+» вы можете включать в учет нужные предлоги и отбрасывать фразы их не содержащие. Пишется вот так:
5. Исключение из учета отдельных слов (минус слова)
Нередко возникает необходимость получить общую статистику по фразе, не уточняя её кавычками, но без учета определенных добавок. Например, продавая какую-то услугу, нам необходимо вычислить спрос на нее. Естественно, существуют люди, желающие получить ее бесплатно – их в расчет брать не желательно.
Исключить слово «бесплатно» мы можем оператором «минус». Впрочем, минус удаляет из статистики любое слов стоящее за ним, не только «бесплатно».
Вот как используется данный синтаксис:
Одновременно можно использовать любое количество минус слов, разделяя их пробелами и ставя перед каждым знак “-“.
6. Объединение статистики по схожим запросам
Существует в Вордстате возможность не только уточнять запросы, но и наоборот – объединять данные по схожим фразам.
Как это работает: Допустим, у вас есть 4 ключа, по которым планируется продвижение страницы – это «яндекс вордстат», «yandex wordstat», «яндекс wordstat» и «yandex вордстат».
Мы можем взять общую статистику по всем 4 запросам. Для этого используем круглые скобки и вертикальную черту (прямой слэш). Внутри скобок слэшем разделяем варианты.
Пример: (слово1|слово2) одинаковая часть
Блоков с круглыми скобками может быть несколько, а общая часть может вовсе отсутствовать, как в на скриншоте ниже:
Key Collector и СловоЕБ
Это комплексная десктопная программа, в которой есть буквально всё для работы с контекстной рекламой, в том числе сбор семантического ядра.
Чтобы сделать парсинг в Key Collector, добавляем фразы:
Запускаем парсинг. Рекомендация: выбирайте глубину 2. Так вы сразу получаете не только результаты парсинга, но и дополнительную выдачу по каждому из них.
Подробнее настройки описаны здесь.
Также Key Collector позволяет очистить семантическое ядро от «мусора», а именно:
- Ключевиков, которые содержат ненужные слова;
- Повторов слов;
- Стоп-слов (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.);
- Запросов с нулевой частотностью.
Есть бесплатный аналог Key Collector – СловоЕБ. Основное его ограничение – в источниках. Он работает только с левой и правой колонкой в Wordstat, Rambler.Adstat и поисковыми подсказками Яндекс и Google.
Для сравнения: Key Collector поддерживает всё вышеперечисленное, плюс Google Ads, подсказки Mail, Wordstat полностью и системы аналитики, установленные на сайте (Google Analytics, Яндекс.Метрика, LiveInternet).
Другие ограничения программы СловоЕБ:
- Проверяет частоту запросов только по Wordstat, а КК также по Yandex.Direct, Google.Ads, LiveInternet, Rambler.Adstat, APIShop.com;
- Оценивает конкурентность запросов для Яндекс и Google, в то время как в КК 4 формулы оценки KEI, которые можно менять вручную.
Однако этого функционала будет вполне достаточно, если у вас небольшой проект.
Приложения
Лидер в этом сегменте – key-collector.ru . Это мощный десктопный инструмент для парсинга ключей из Вордстата. Не нужно вручную собирать, программа расширяет пул запросов исходя из вашего маленького списка. Вам нужно только определить основные ниши и указать приложению, что искать.
У программы есть пара недостатков:
- сложности в настройках. Вот ссылка на гайд в помощь – настройки Key Collector с нуля.
- приложение платное. Вот расценки:
Есть бесплатный аналог с более узким функционалом – «Словоёб» (уж простите, такое название, создатели были очень креативными).
Для ведения нескольких или крупных проектов, такие приложения просто незаменимы. Потратьте полчаса на настройку один раз и вы сэкономите десятки часов при постоянном использовании программ в продвижении проектов.
Еще обратите внимание на дополнительный источник ключей – это «Букварикс». Программа похожа на Wordstat, но информация по запросам разнится из-за разных алгоритмов сбора
Если вы хотите научиться использовать эти приложения, собирать правильную семантику и продвигать сложные проекты тогда вам сюда:
А если планируете настраивать контекстную рекламу, то вам подойдёт вот эта подборка курсов:
КМС Google
Содержание в Интернете быстро меняется, а вместе с ним – и список площадок. Чтобы охватить их, достаточно выбрать темы, которые соответствуют вашей рекламе.
В КМС ключевики (причем не отдельные слова, а группы из 5-7 слов) – это тематические указатели интересов целевой аудитории или контента площадок для показа рекламы. Нет смысла собирать вложенные запросы:
- Аренда склада;
- Аренда склада от собственника;
- Аренда склада от собственника в Перми.
Верный вариант:
- Склад;
- Помещение;
- Аренда;
- Ответственное хранение.
Когда составляете семантическое ядро, учитывайте то, на какой спрос вы ориентируетесь, а также то, как потенциальные клиенты могут искать вас в интернете. Высоких вам конверсий! Еще в тему – статья Семантическое ядро для контекстной рекламы: алгоритмы для разных типов кампаний. Там вы найдете нюансы и хитрости работы с семантикой по бренду, по сложным услугам, для фидов.