Find и grep в linux как инструмент для администрирования
Содержание:
- 11. Параметры для использования с командой Tree в Linux
- Команда sed в Linux
- 2. Примеры использования команды Grep
- Приведем примеры
- Matching control options
- Использование регулярных выражений
- Основные команды Sed
- Замена слова в файле
- Замена слова в файле и вывод результата в другой файл
- Замена слова в нескольких файлах одновременно
- Отбросить всё, что левее определённого слова
- Отбросить всё, что правее определённого слова
- Экранирование символов в sed
- Два условия одновременно в Sed
- Удалить строку
- Получить диапазон строк
- Работа
- Параметры grep
- Кванторы
- Regular expressions
- Анкоры
11. Параметры для использования с командой Tree в Linux
Параметры для использования с деревом
Далее Solvetic объяснит доступные параметры для использования с Tree:
-a: распечатать все файлы, помните, что по умолчанию дерево не печатает скрытые файлы.
-d: список только каталогов.
-l: продолжить символические ссылки, если они указывают на каталоги, притворяясь каталогами.
-f: вывести префикс полного пути к объектам.
-x: остается только в текущей файловой системе.
-L Level: позволяет определить максимальную глубину просмотра дерева каталогов в результате.
-R: Действовать рекурсивно, пересекая дерево в каталогах каждого уровня, и в каждом из них оно будет выполняться. дерево снова, добавив `-o 00Tree.html ‘.
-P шаблон: список только файлов, которые соответствуют шаблону подстановки.
-I шаблон: не перечислять файлы, которые соответствуют шаблону подстановки.
—matchdirs. Этот параметр указывает шаблон соответствия, который позволяет применять шаблон только к именам каталогов.
—prune: этот параметр удаляет пустые каталоги из выходных данных.
—noreport: пропускает печать файла и отчета каталога в конце списка выполненного дерева.
Общие параметры дерева
Это общие параметры, доступные для дерева, но у нас также есть эксклюзивные параметры для файлов, это:
-q: печатать непечатаемые символы в именах файлов.
-N: печать непечатных символов.
-Q: его функция заключается в назначении имен файлов в двойных кавычках.
-p: вывести тип файла и разрешения для каждого файла в каталоге.
-u: распечатать имя пользователя или UID файла.
-s: вывести размер каждого файла в байтах, а также его имя.
-g Распечатать имя группы или GID файла.
-h: его функция — распечатывать размер каждого файла разборчиво для пользователя.
—du: Он действует в каждом каталоге, генерируя отчет о его размере, включая размеры всех его файлов и подкаталогов.
—si: он использует степени 1000 (единицы СИ) для отображения размера файла.
-D: Распечатать дату последнего изменения файлов.
-F: Ваша задача — добавить `/ ‘для каталогов, a` =’ для файлов сокетов, a` * ‘для исполняемых файлов, `>’ для дверей (Solaris) и a` | ‘ для FIFO.
—inodes: вывести номер инода файла или каталога.
- —device: вывести номер устройства, к которому относится файл или каталог в результате.
- -v: Сортировать вывод по версии.
-U: не упорядочивает результаты.
-r: сортировать вывод в обратном порядке.
-t: сортировать результаты по времени последней модификации, а не по алфавиту.
-S: активировать линейную графику CP437
-n: отключает раскраску результата.
-C: активирует раскраску.
-X: активировать вывод XML.
-J: активировать вывод JSON.
-H baseHREF: активирует вывод HTML, включая ссылки HTTP.
—help: Помощь дерева доступа.
—version: показывает используемую версию команды Tree.
С помощью этих двух команд стало возможным гораздо более полное администрирование каждой задачи, выполняемой над файлами в Linux, дополняющей задачи поиска или управления этими файлами и доступа к интегральным результатам по мере необходимости.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
2. Примеры использования команды Grep
Теперь мы увидим, как использовать команду Grep в Linux.
Как использовать Grep в общем
Чтобы понять, как работает Grep, мы посмотрим в каталоге / etc / passwd все результаты, связанные с нашим пользователем:
grep solvetic / etc / passwd

В качестве дополнительного момента помните, что можно сказать, что grep игнорирует прописные и строчные буквы в результатах, для этого мы выполним следующее:
grep -i "resoltic" / etc / passwd

Grep идеально подходит для поиска определенных терминов в известных файлах, например, мы выполним следующий поиск:
grep Solvetic Solvetic.txt

Этот же термин можно искать в разных файлах одновременно, для этого мы будем использовать следующую строку:
grep Solvetic Solvetic.txt Solvetic1.txt

Более сокращенный способ сделать это — выполнить следующее:
grep solvetic *. *

Как использовать grep для перенаправления результатов в файл в Linux
Это полезно в тех случаях, когда мы должны выполнить административные задачи над файлами позже, поэтому можно перенаправить вывод команды grep в определенный файл, например, мы сделаем следующее:
grep Solvetic Solvetic.txt> Solvetic2.txt

Как использовать grep для поиска в каталогах
Благодаря параметру -r мы сможем найти значение в доступных подкаталогах, выполним следующее:
grep -r Solvetic / домашний / решающий

Как использовать grep для отображения номера строки
Для задач аудита или расширенной поддержки идеально отображать номер строки, в которой находится указанный шаблон поиска, для этого мы можем использовать параметр -n следующим образом. Там мы находим номер строки, где находится каждое значение.
grep -n Solvetic Solvetic.txt

Как использовать grep для выделения результатов
Поскольку мы знаем, что текст во многих случаях может сбить с толку, по этой причине решение состоит в том, чтобы выделить критерии поиска, которые фокусируют наше представление непосредственно на этой строке, для этого мы будем использовать параметр цвета, например:
grep -color Solvetic Solvetic.txt

Как использовать grep для отображения строк, начинающихся или заканчивающихся указанным шаблоном
Мы можем захотеть визуализировать только результаты строк, которые начинаются или заканчиваются критериями поиска, для этого, если мы хотим найти строки, которые начинаются, мы будем использовать следующую строку:
grep ^ Solvetic Solvetic.txt

Теперь, чтобы отобразить строки, которые заканчиваются, мы будем использовать следующее:
grep Solvetic $ Solvetic.txt

Как использовать grep для печати всех строк, не видя совпадающих
Если мы хотим увидеть все строки, кроме тех, где задано желаемое значение, мы должны использовать параметр -v следующим образом:
grep -v Solvetic Solvetic.txt

Как использовать grep с другими командами
Grep, как и многие команды Linux, можно использовать одновременно с другими командами для получения более четких результатов, например, если мы хотим развернуть процессы HTTP, мы будем использовать grep рядом с ps следующим образом:
ps -ef | grep http

Как использовать grep, чтобы посчитать, сколько слов повторяется в файле
Если мы хотим узнать, сколько раз шаблон повторяется в данном файле, мы будем использовать параметр -c:
grep -c Solvetic Solvetic.txt

Как использовать grep для обратного поиска
Хотя это звучит странно, это не что иное, как отображение в результате слов, которые мы не указываем, это достигается с помощью параметра -v:
grep -v Solvetic Solvetic2.txt

Как использовать grep для просмотра сведений об оборудовании
Ранее мы видели, что мы можем комбинировать grep с другими командами для отображения результата, ну, если мы хотим получить конкретные сведения об оборудовании, мы можем использовать cat с grep следующим образом:
cat / proc / cpuinfo | grep -i 'Модель'

Во всем мире мы узнали, как использовать команду grep для доступа к гораздо более конкретным результатам поиска в Linux.
Приведем примеры
. (точка)
Используется для соответствия любому символу, который встречается в поисковом запросе. Например, можем использовать точку как:
Это регулярное выражение означает, что мы ищем слово, которое начинается с ‘d’, оканчивается на ‘g’ и может содержать один любой символ в середине файла с именем ‘file1’. Точно так же мы можем использовать символ точки любое количество раз для нашего шаблона поиска, например:
Этот поисковый термин будет искать слово, которое начинается с ‘T’, оканчивается на ‘h’ и может содержать любые шесть символов в середине.
Квадратные скобки используются для определения диапазона символов. Например, когда нужно искать один из перечисленных символов, а не любой символ, как в случае с точкой:
Здесь мы ищем слово, которое начинается с ‘N’, оканчивается на ‘n’ и может иметь только ‘o’, ‘e’ или ‘n’ в середине. В квадратных скобках можно использовать любое количество символов. Мы также можем определить диапазоны, такие как ‘a-e’ или ‘1-18’, как список совпадающих символов в квадратных скобках.
Это похоже на оператор отрицания для регулярных выражений. Использование означает, что поиск будет включать в себя все символы, кроме тех, которые указаны в квадратных скобках. Например:
Это означает, что у нас могут быть все слова, которые начинаются с ‘St’, оканчиваются буквой ‘d’ и не содержат цифр от 1 до 9.
До сих пор мы использовали примеры регулярных выражений, которые ищут только один символ. Но что делать в иных случаях? Допустим, если требуется найти все слова, которые начинаются или оканчиваются символом или могут содержать любое количество символов в середине. С этой задачей справляются так называемые метасимволы-квантификаторы, определяющие сколько раз может встречаться предшествующее выражение: + * & ?
{n}, {n m}, {n, } или { ,m} также являются примерами других квантификаторов, которые мы можем использовать в терминах регулярных выражений.
* (звездочка)
На следующем примере показано любое количество вхождений буквы ‘k’, включая их отсутствие:
Это означает, что у нас может быть совпадение с ‘lake’ или ‘la’ или ‘lakkkkk’.
+
Следующий шаблон требует, чтобы хотя бы одно вхождение буквы ‘k’ в строке совпадало:
Здесь буква ‘k’ должна появляться хотя бы один раз, поэтому наши результаты могут быть ‘lake’ или ‘lakkkkk’, но не ‘la’.
?
В следующем шаблоне результатом будет строка bb или bab:
С заданным квантификатором ‘?’ мы можем иметь одно вхождение символа или ни одного.
Важное примечание! Предположим, у нас есть регулярное выражение:
И мы получаем результаты ‘Small’, ‘Silly’, и ещё ‘Susan is a little to play ball’. Но почему мы получили ‘Susan is a little to play ball’, ведь мы искали только слова, а не полное предложение?
Все дело в том, что это предложение удовлетворяет нашим критериям поиска: оно начинается с буквы ‘S’, имеет любое количество символов в середине и заканчивается буквой ‘l’. Итак, что мы можем сделать, чтобы исправить наше регулярное выражение, чтобы в качестве выходных данных мы получали только слова вместо целых предложений.
Для этого в регулярное выражение нужно добавить квантификатор ‘?’:
или символ экранирования
Символ » используется, когда необходимо включить символ, который является метасимволом или имеет специальное значение для регулярного выражения. Например, требуется найти все слова, заканчивающиеся точкой. Для этого можем использовать выражение:
Оно будет искать и сопоставлять все слова, которые заканчиваются точкой.
Итак, вы получили общее представление о том, как работают регулярные выражения. Практикуйтесь как можно больше, создавайте регулярные выражения и старайтесь включать их в свою работу как можно чаще. Проверять правильность использования своих регулярных выражений на конкретном примере можно на специальном сайте.
Matching control options
| -e PATTERN, —regexp=PATTERN | Use PATTERN as the pattern to match. This can specify multiple search patterns, or to protect a pattern beginning with a dash (—). |
| -f FILE, —file=FILE | Obtain patterns from FILE, one per line. |
| -i, —ignore-case | Ignore case distinctions in both the PATTERN and the input files. |
| -v, —invert-match | Invert the sense of matching, to select non-matching lines. |
| -w, —word-regexp | Select only those lines containing matches that form whole words. The test is that the matching substring must either be at the beginning of the line, or preceded by a non-word constituent character. Or, it must be either at the end of the line or followed by a non-word constituent character. Word-constituent characters are letters, digits, and underscores. |
| -x, —line-regexp | Select only matches that exactly match the whole line. |
| -y | The same as -i. |
Использование регулярных выражений
Истинная сила grep заключается в возможности применения для поиска соответствий регулярным выражениям. В регулярных выражениях в аргументе ШАБЛОН используются специальные символы для охвата более широкого диапазона строк. Рассмотрим простой пример.
Допустим, требуется найти каждое появление фразы, похожей на «our products», которая всегда должна начинаться с «our» и заканчиваться на «products». Для этого нужно указать такой шаблон: «our.*products».
В регулярных выражениях точка («.») интерпретируется как маска для одного символа. Она означает «подойдет любой символ на этом месте». Звездочка («*») означает «подойдет предыдущий символ в количестве от нуля и более». Таким образом, комбинация «.*» означает, что подойдет любой символ в любом количестве. Например, «our amazing products», «ours, the best-ever products» и даже «ourproducts» будут соответствовать выражению. А так как указана опция –i, ему будут соответствовать также «OUR PRODUCTS» и «OuRpRoDuCtS». При запуске команды с этим регулярным выражением мы получим дополнительные совпадения:
$ grep –-color –n -i «our.*products» *.html product-details.html:27:<p><b>OUR PRODUCTS</b></p> product-details.html:59:<p class=”products-searchbox”>To search a comprehensive list of our products type your search term in the box below and click the magnifying glass</p> product-replacement.html:58:<p>If you experience dissatisfaction with any of our fine products, do not hesitate to contact us using the form below.</p> $
Была найдена фраза «our fine products».
Grep – мощный инструмент работы с текстовыми файлами. При умелом использовании регулярных выражений он предоставляет еще более широкие возможности. Здесь рассмотрены наиболее типичные примеры использования команды. Другие опции командной строки можно узнать, запустив команду с опцией —help.
Основные команды Sed
Для того чтобы применить SED достаточно ввести в командную строку
echo ice | sed s/ice/fire/
Результат:
fire
Замена слова в файле
Обычно SED применяют к файлам, например к логам или конфигам.
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим заменить слово Here на There
sed ‘s/HereThere/’ input.txt
Результат будет выведен в консоль:
There is a String
There is an Integer
There is a Float
Если нужно не вывести в консоль а изменить содержание файла — используем опцию -i
sed -i ‘s/HereThere/’ input.txt
В этом случае перепишется исходный файл input.txt
Рассмотрим пример посложнее. Файл input.txt теперь выглядит так:
sed ‘s/HereThere/’ input.txt
Как Вы сейчас увидите, замена произойдёт только по одному разу в строке
There is an Apple. Here is a Pen. Here is an ApplePen
Integer is There
There is a Float
There is a Pen. Here is a Pineapple. Here is a PineapplePen
Чтобы заменить все слова нужна опция g
sed ‘s/HereThere/g’ input.txt
There is an Apple. There is a Pen. There is an ApplePen
Integer is There
There is a Float
There is a Pen. There is a Pineapple. There is a PineapplePen

Замена слова в файле и вывод результата в другой файл
Та же замена, но с выводом в новый текстовый файл, который мы назовём output:
sed ‘s/HereThere/’ input.txt > output.txt
Замена слова в нескольких файлах одновременно
Если нужно обработать сразу несколько файлов: например файл 1.txt с содержанием
И файл 2.txt с содержанием
Это можно сделать используя *.txt
sed ‘s/HereThere/’ *.txt > output.txt
На выходе файл output.txt будет выглядеть так
Отбросить всё, что левее определённого слова
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится левее слова it, включая слово it, и записать в файл.
sed ‘s/^.*it//’ input.txt > output.txt
^ означает, что мы стартуем с начала строки
Результат:
has a Name
has a Name
has a Name
Для доступности объясню синтаксис сравнив две команды. Посмотрите внимательно, когда мы заменяем
слово Here на There.
There находится между двумя слэшами. Раскрашу их для наглядности в зелёный и
красный.
sed ‘s/HereThere‘
А когда мы хотим удалить что-то, мы сначала описываем, что мы хотим удалить. Например, всё от
начала строки до слова it.
Теперь в правой части условия, где раньше была величина на замену, мы
ничего не пишем, т.е. заменяем на пустое место. Надеюсь, логика понятна.
sed ‘s/^.*it’ > output.txt
Отбросить всё, что правее определённого слова
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится правее слова is, включая слово is, и записать в файл.
sed ‘s/is.*//’ > output.txt
Результат:
Экранирование символов в sed
Специальные символы экранируются с помощью \
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится левее /a, включая /a, и записать в файл.
sed ‘s/^.*/a//’ > output.txt
В результате получим ошибку
-e expression #1, char 15: unknown option to `s’
Чтобы команда заработала нужно добавить \ перед /
sed ‘s/^.*\/a//’ > output.txt
Результат:
Два условия одновременно в Sed
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится левее /b, включая /b, и всё, что правее
has.
Таким образом, в каждой строчке должно остаться только слово it.
Нужно учесть необходимость экранирования специального символа / а также мы хотим
направить вывод в файл.
sed ‘s/^.*\/b//
;
s/has.*//’ input.txt > output.txt
Результат:
Допустим Вы хотите удалить все строки после третьей
sed 3q input.txt > output.txt
Удалить строку
Допустим Вы хотите удалить все строки где встречается слово Apple в файле input.txt
Сделать это можно с помощью опции d
sed ‘/Apple/d‘ input.txt > output.txt
Результат:
Теперь сделаем более сложное условие — удалим все строки где есть слово Pineapple и слово Integer
sed ‘/Pineapple\|Integer/d’ input.txt > output.txt
| выступает в роли логического ИЛИ
\ нужна чтобы экранировать |
Результат:
Получить диапазон строк
В случае, когда Вы работаете с большими файлами, например с логами, часто бывает нужно
получить только определённые строки, например, в момент появления бага.
Копировать из UI командной строки не всегда удобно, но если Вы примерно представляете
диапазон нужных строк — можно скопировать только их и записать в отдельный файл.
Например, Вам нужны строки с 9570 по 9721
sed -n ‘9570,9721p;9722q’ project-2019-10-03.log > bugFound.txt
Работа
Задачи, которые могут выполнять троянские программы, бесчисленны (как бесчисленны и существующие ныне в мире компьютерные вредоносные программы), но в основном они идут по следующим направлениям:
- нарушение работы других программ (вплоть до зависания компьютера, решаемого лишь перезагрузкой, и невозможности их запуска);
- настойчивое, независимое от владельца предлагание в качестве стартовой страницы спам-ссылок, рекламы или порносайтов;
- распространение по компьютеру пользователя порнографии;
- превращение языка текстовых документов в бинарный код;
- мошенничество (например, при открывании определённого сайта пользователь может увидеть окно, в котором ему предлагают сделать определённое действие, иначе произойдёт что-то труднопоправимое — бессрочная блокировка пользователя со стороны сайта, потеря банковского счета и т. п., иногда за деньги, получение доступа к управлению компьютером и установки вредоносного ПО);
- простое списывание
Параметры grep
recursive -r
—Опция
Еще больше увеличит зону опция поисков -r, которая заставит
команду grep обследовать рекурсивно все дерево указанной
директории, то субдиректории есть, субдиректории субдиректорий, и
так далее файлов до вплоть. Например:
grep -r menu /boot /grub/boot/grub.txt:Highlight the entry menu you want to edit and then 'e', press
/boot/grub/grub.txt:the Press key to return to the menu
GRUB. /boot/grub/menu.lst:# configuration GRUB file
‘/boot/grub/menu.boot’. /lst/grub/menu.lst:gfxmenu
(boot,3)/hd0/message
Опция -i
—ignore-case
команде Приказывает игнорировать регистр символов, таким
поиск, образом будет производиться как среди так, заглавных и среди
строчных букв.
Опция -c
—Эта
count опция не выводит строки, а подсчитывает строк количество, в
которых обнаружен ОБРАЗЕЦ. Например:
root -c grep /etc/group 8
То есть в восьми файла строках /etc/group встречается сочетание
root символов.
—line-number
При этой использовании опции вывод команды grep указывать будет
номера строк, содержащих ОБРАЗЕЦ:
invert -v
—Опция-match
Выполняет работу, обратную выводит — обычной строки, в которых
ОБРАЗЕЦ не встречается:
print -v grep /etc/printcap # # # for you (at initially least), such as apsfilter # (/usr/share/SETUP/apsfilter, used in conjunction with the # lpd LPRng daemon), or with the web provided interface by the # (if you use CUPS).
word -w
—Опция-regexp
Заставит команду grep только искать строки, содержащие все слово
фразу или, составляющую ОБРАЗЕЦ. Например:
grep -w "example ко" длинная/*
Не дает вывода, то есть не находит содержащих, строк выражение
«длинная ко». А вот команда:
длинная -w "grep коса" example/* example/alice.длинная:txt коса!
находит точное соответствие в alice файле.txt.
Опция -x
—line-regexp
более Еще строгая. Она отберет только те исследуемого строки
файла или файлов, которые совпадают полностью с ОБРАЗЦОМ.
grep -x "1234" example/* 123/example.txt:1234
Внимание: Мне собственном (на попадались компьютере)
версии grep (например, которых 2.5), в GNU опция -x работала
неадекватно. В то же время, версии другие (GNU 2.5.1) работали
прекрасно
Если ладится-то не что с этой опцией, попробуйте другую
или, версию обновите свою.
Опция -l
—files-matches-with
Команда grep с этой опцией не строки возвращает, содержащие
ОБРАЗЕЦ, но сообщает лишь файлов имена, в которых данный образец
найден:
Алиса -l 'grep' example/* example/alice.txt
что, Замечу сканирование каждого из заданных файлов только
продолжается до первого совпадения с ОБРАЗЦОМ.
Опция -L
—without-files-match
Наоборот, сообщает имена файлов тех, где не встретился
ОБРАЗЕЦ:
grep -L 'example' Алиса/* example/123.txt example/txt.ast
Как мы имели случай заметить, grep команда, в поисках
соответствия ОБРАЗЦУ, просматривает содержимое только файлов, но не
их имена. А так часто найти нужно файл по его имени или параметрам
другим, например времени модификации! Тут придет нам на помощь
простейший программный канал (При). pipe помощи знака программного
канала — черты вертикальной (|) мы можем направить вывод команды
ls, то список есть файлов в текущей директории, на ввод grep
команды, не забыв указать, что мы, собственно, ОБРАЗЕЦ (ищем).
Например:
ls | grep grep grep/ txt-ru.grep
Находясь в директории Desktop, мы «попросили» Рабочем на найти
столе все файлы, в названии есть которых выражение «grep». И нашли
одну grep директорию/ и текстовой файл grep-ru.txt, данный я в
который момент и пишу.
Если мы хотим другим по искать параметрам файла, а не по его
имени, то применить следует команду ls -l, которая выводит файлы со
параметрами всеми:
ls -l | grep 2008-12-30 -rw-r--r-- 1 ya users 27 2008-12-30 08:06 txt.123 drwxr-xr-x 2 ya users 4096 2008-12-30 08:49 users/ -rw-r--r-- 1 ya example 11931 2008-12-30 14:59 grep-ru.txt
И получили мы вот список всех файлов, модифицированных 30
2008 декабря года.
Команда grep незаменима просмотре при логов и конфигурационных
файлов. Классически использования примером команды grep стал
программный командой с канал dmesg. Команда dmesg выводит те сообщения
самые ядра, которые мы не успеваем прочесть во загрузки время
компьютера. Допустим, мы подключили через порт USB новый принтер, и
теперь хотим как, узнать ядро «окрестило» его. Дадим команду
такую:
dmesg | grep -i usb
Опция -i так, необходима как usb часто пишется буквами
заглавными. Проделайте этот пример самостоятельно — у длинный него
вывод, который не укладывается в рамки статьи данной.
Кванторы
Расширенные регулярные выражения поддерживают несколько способов указания количества раз, которое совпадает элемент.
? – совпадение элемента ноль или один раз
Этот квантор по сути сводится к «сделать предыдущий элемент опциональным». Допустим, мы хотим проверить телефонный номер на правильность, и мы считаем телефонный номер правильным, если он соответствует одной из этих двух форм:
(nnn) nnn-nnnn nnn nnn-nnnn
где «n» — это число. Мы можем сконструировать регулярное выражение вроде такого:
^\(?\)? -$
В этом выражении мы поставили за символами скобок знаки вопроса, чтобы указать, что они должны встречаться ноль или один раз. Опять, поскольку круглые скобки являются обычно метасимволами (в ERE), перед ними мы поставили обратные слеши, благодаря которым они стали обрабатываться как литералы.
Давайте попробуем это:
echo "(555) 123-4567" | grep -E '^\(?\)? -$' (555) 123-4567 echo "555 123-4567" | grep -E '^\(?\)? -$' 555 123-4567 echo "AAA 123-4567" | grep -E '^\(?\)? -$'
Здесь мы видим, что выражение соответствует обоим формам телефонного номера, но не соответствует одному, содержащему не-цифровые символы.
* — совпадение элемента ноль или более раз
Как и метасимвол ?, * используется для обозначения опционального элемента; тем не менее, в отличие от ?, элемент может встречаться любое количество раз, не только одиножды. Допустим мы хотим увидеть, является ли строка предложением; это так, если она начинается с заглавной буквы, затем содержит любое количество больших и маленьких букв, пробелов и заканчивается точкой. Для соответствия этому (очень приблизительному) определению предложения, вы должны использовать регулярное выражение вроде такого:
] ]*\.
Выражение состоит из трёх пунктов: выражение в квадратных скобках содержащее класс символов , выражение в квадратных скобках, содержащее оба класса символов и и пробел, в конце идёт точка, экранированная обратным слешем. Второй элемент заканчивается метасимволом *, благодаря которому после начальной заглавной буквы в нашем предложении за ней могут следовать любое количество заглавных и строчных букв и пробелов, и оно всё равно считается подходящим:
echo "This works." | grep -E '] ]*\.' This works. echo "This Works." | grep -E '] ]*\.' This Works. echo "this does not" | grep -E '] ]*\.'
Выражение соответствует первым двум проверкам, но не третьей, поскольку в ней отсутствует символ требуемой начальной заглавной буквы и конечная точка.
+ — совпадение элемента один или более раз
Метасимвол + работает очень похоже на *, кроме того, что он требует хотя бы один экземпляр предшествующего элемента, чтобы привести к совпадению. Это регулярное выражение будет соответствовать только строчкам, состоящих из групп из одного или более алфавитных символов, разделённых одним пробелом:
^(]+ ?)+$
echo "This that" | grep -E '^(]+ ?)+$' This that echo "a b c" | grep -E '^(]+ ?)+$' a b c echo "a b 9" | grep -E '^(]+ ?)+$' echo "abc d" | grep -E '^(]+ ?)+$'
Мы видим, что это выражение не соответствует строке «a b 9», поскольку она содержит неалфавитный символ; и не соответствует «abc d», поскольку символы «c» и «d» разделены более чем одним символом пробела.
{ } — совпадение элемента указанное количество раз
Метасимволы { и } используются для выражения минимального и максимального числа требуемых соответствий. Они могут задаваться четырьмя различными способами:
| Спецификатор | Значение |
|---|---|
| {n} | Соответствие предыдущего элемента, если он встречается ровно n раз. |
| {n,m} | Соответствие предыдущего элемента, если он встречается по меньшей мере n раз, но не более чем m раз. |
| {n,} | Соответствие предыдущего элемента, если он встречается n или более раз. |
| {,m} | Соответствие предыдущего элемента, если он встречается не более чем m раз. |
Возвращаясь к нашему раннему примеру с телефонными номерами, мы можем использовать этот метод указания повторений для упрощения оригинального регулярного выражения с:
^\(?\)? -$
до:
^\(?{3}\)? {3}-{4}$
Давайте испытаем его:
echo "(555) 123-4567" | grep -E '^\(?{3}\)? {3}-{4}$'
(555) 123-4567
echo "555 123-4567" | grep -E '^\(?{3}\)? {3}-{4}$'
555 123-4567
echo "5555 123-4567" | grep -E '^\(?{3}\)? {3}-{4}$'
Как мы можем видеть, наше улучшенное регулярное выражение может успешно проверять правильность телефонных номеров как со скобками, так и без скобок, и при этом отбрасывает номера, которые имеют неправильный формат.
Regular expressions
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, by using various operators to combine smaller expressions.
grep understands three different versions of regular expression syntax: «basic» (BRE), «extended» (ERE) and «perl» (PRCE). In GNU grep, there is no difference in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl regular expressions give additional functionality.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any metacharacter with special meaning may be quoted by preceding it with a backslash.
The period (.) matches any single character.
Анкоры
Символ каретки (^) и знак доллара ($) считаются в регулярных выражениях анкорами. Это означает, что они вызывают совпадение, только если регулярное выражение найдено в начале строки (^) или в конце строки ($):
grep -h '^zip' dirlist*.txt zip zipcloak zipdetails zipgrep zipinfo zipnote zipsplit
grep -h 'zip$' dirlist*.txt gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip unzip zip
grep -h '^zip$' dirlist*.txt zip
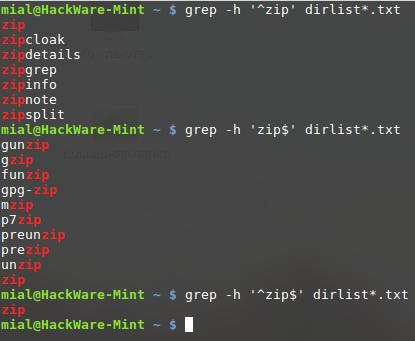
Здесь мы искали по спискам файлов строку «zip», расположенную в начале строки, в конце строки, а также в строке, где она была бы одновременно и в начале, и в конце (т.е. вся строка содержала бы только «zip»)
Обратите внимание, что регулярное выражение «^$» (начало и конец между которыми ничего нет) будет соответствовать пустым строкам.
Небольшое лирическое отступление: помощник по разгадыванию кроссвордов
Даже с нашими ограниченными на данный момент познаниями в регулярных выражениях мы можем делать что-то полезное.
Если вы когда-нибудь разгадывали кроссворды, то вам нужно было решать задачи вроде «что за слово из пяти букв, где третья буква «j», а последняя буква «r», которое означает…». Этот вопрос может заставить задуматься. Знаете ли вы, что в системе Linux есть словарь? А он есть. Загляните в директорию /usr/share/dict, там вы можете найти один или несколько словарей. Словари, размещённые там, это просто длинные списки слов по одному на строку, расположенные в алфавитном порядке. В моей системе файл словаря содержит 99171 слов. Для поиска возможных ответов на вышеприведённый вопрос кроссворда, мы можем сделать так:
grep -i '^..j.r$' /usr/share/dict/american-english Major major
Используя это регулярное выражение, мы можем найти все слова в нашем файле словаря, которое имеет длину в пять букв, имеет «j» в третьей позиции и «r» в последней позиции.
В примере использовался английский файл словаря, поскольку он присутствует в системе по умолчанию. Предварительно скачав соответствующий словарь, вы можете делать аналогичные поиски по словам на кириллице или из любых других символов.