Справочник по языку python3
Содержание:
Содержание справочника по Python3:
Определение функций в Python.
Ключевое слово def вводит определение функции . За ним должно следовать имя функции и заключенный в скобки список формальных параметров. Операторы, которые формируют тело функции, начинаются со следующей строки и должны иметь отступ.
Приоритет операций в выражениях в Python.
Выражение — это код, который интерпретатор Python вычисляет для получения значения. Операции с более высоким приоритетом выполняются до выполнения операций с более низким приоритетом.
Строковые и байтовые литералы.
Байтовые литералы всегда начинаются с префикса ‘b’ или ‘B’. Как строковые, так и байтовые литералы могут дополнительно иметь префикс в виде буквы ‘r’ или ‘R’. Такие строки называются необработанными.
Встроенные константы языка Python.
Пространство имен языка Python имеет небольшое количество встроенных констант. Это False, True, None, NotImplemented, __debug__
Инструкция del в Python.
Инструкция `del` не удаляет объекты в буквальном смысле, она лишь открепляет ссылки, разрывая связь между именем и объектом. Удаление объекта произойдет как следствие работы сборщика мусора.
Приемы работы со строками в Python.
Язык программирования Python может манипулировать строками, которые могут быть записаны несколькими способами. Текстовые строки могут быть заключены в одинарные кавычки (‘…’) или двойные кавычки («…»), что в результате будет одно и то же.
Использование регулярных выражений в Python.
Регулярные выражения — это шаблоны соответствия текста, описанные в формальном синтаксисе и могут включать в себя буквальное сопоставление текста, повторение, ветвление и другие сложные правила. Регулярные выражения обычно используются в приложениях, которые требуют тонкую обработку текста.
Использование списков list в Python.
Язык программирования Python имеет несколько составных типов данных, используемых для группировки значений. Наиболее универсальным является список, который можно записать в виде списка значений (элементов), разделенных запятыми, в квадратных скобках.
Использование кортежей tuple в Python.
Кортежи являются неизменяемыми и обычно содержат гетерогенную последовательность элементов, доступ к которым осуществляется через распаковку или индексацию, или даже по атрибуту в случае `collections.namedtuple()`.
Использование словарей dict в Python.
Основные использование словаря — это хранение значения с некоторым ключом и извлечение значения из словаря, заданного ключом. Лучше всего рассматривать словарь как набор пар «ключ-значение» с требованием, чтобы ключи были уникальными в пределах одног
Использование множеств set в Python.
Основные виды использования множеств включают вхождение/наличие элемента и устранение дубликатов записей.
Итераторы в Python.
Функция возвращает объект итератора, который определяет метод __next__(), который, в свою очередь обращается к элементам в контейнере по одному за раз. Когда нет больше элементов, __next__() возбуждает исключение StopIteration
Функция генератора в Python.
Генераторы используют оператор yield всякий раз, когда они хотят вернуть данные. Каждый раз, когда вызывается встроенная функция next(), генератор возобновляет работу с того места, где он остановился.
Работа с файлами в Python.
При доступе к файлу в операционной системе требуется указать путь к файлу. Путь к файлу — это строка, которая представляет местоположение файла.
Система импорта в Python.
При первом импорте модуля Python выполняет поиск модуля и, если он найден, создает объект модуля, инициализируя его. Если именованный модуль не может быть найден, то вызывается исключение ModuleNotFoundError.
Загрузить файлы Excel в виде фреймов Pandas
Все, среда настроена, вы готовы начать импорт ваших файлов.
Один из способов, который вы часто используете для импорта ваших файлов для обработки данных, — с помощью библиотеки Pandas. Она основана на NumPy и предоставляет простые в использовании структуры данных и инструменты анализа данных Python.
Эта мощная и гибкая библиотека очень часто используется дата-инженерами для передачи своих данных в структуры данных, очень выразительных для их анализа.
Если у вас уже есть Pandas, доступные через Anaconda, вы можете просто загрузить свои файлы в Pandas DataFrames с помощью pd.Excelfile():
Если вы не установили Anaconda, просто выполните pip install pandas, чтобы установить библиотеку Pandas в вашей среде, а затем выполните команды, которые включены в фрагмент кода выше.
Проще простого, да?
Для чтения в файлах .csv у вас есть аналогичная функция для загрузки данных в DataFrame: read_csv(). Вот пример того, как вы можете использовать эту функцию:
Разделитель, который будет учитывать эта функция, по умолчанию является запятой, но вы можете указать альтернативный разделитель, если хотите. Перейдите к документации, чтобы узнать, какие другие аргументы вы можете указать для успешного импорта!
Обратите внимание, что есть также функции read_table() и read_fwf() для чтения файлов и таблиц с фиксированной шириной в формате DataFrames с общим разделителем. Для первой функции разделителем по умолчанию является вкладка, но вы можете снова переопределить это, а также указать альтернативный символ-разделитель
Более того, есть и другие функции, которые вы можете использовать для получения данных в DataFrames: вы можете найти их .
Как записать Pandas DataFrames в файлы Excel
Допустим, что после анализа данных вы хотите записать данные обратно в новый файл. Есть также способ записать ваши Pandas DataFrames обратно в файлы с помощью функции to_excel().
Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные в несколько листов в файле .xlsx:
Обратите внимание, что в приведенном выше фрагменте кода вы используете объект ExcelWriter для вывода DataFrame. Иными словами, вы передаете переменную Writer в функцию to_excel() и также указываете имя листа
Таким образом, вы добавляете лист с данными в существующую рабочую книгу: вы можете использовать ExcelWriter для сохранения нескольких (немного) разных DataFrames в одной рабочей книге
Иными словами, вы передаете переменную Writer в функцию to_excel() и также указываете имя листа. Таким образом, вы добавляете лист с данными в существующую рабочую книгу: вы можете использовать ExcelWriter для сохранения нескольких (немного) разных DataFrames в одной рабочей книге.
Все это означает, что если вы просто хотите сохранить один DataFrame в файл, вы также можете обойтись без установки пакета XlsxWriter. Затем вы просто не указываете аргумент движка, который вы передаете в функцию pd.ExcelWriter(). Остальные шаги остаются прежними.
Аналогично функциям, которые вы использовали для чтения в файлах .csv, у вас также есть функция to_csv() для записи результатов обратно в файл, разделенный запятыми. Он снова работает так же, как когда вы использовали его для чтения в файле:
Если вы хотите иметь файл, разделенный табуляцией, вы также можете передать \ t аргументу sep
Обратите внимание, что есть другие функции, которые вы можете использовать для вывода ваших файлов. Вы можете найти их все
Методы открытого файла.
Python предоставляет основные методы, необходимые для работы с файлами по умолчанию. Вы можете сделать большую часть манипуляций с файлом, используя объект файла .
Прежде чем вы сможете прочитать или записать в файл, вы должны открыть его с помощью встроенной функции . Эта функция создает , который будет использоваться для вызова методов, которые представлены ниже:
Метод file.close() в Python, закрывает файл.
Метод file.close() закрывает открытый файл. Закрытый файл больше не может быть прочитан или записан. Любая операция, которая требует, чтобы файл был открыт, вызовет исключение ValueError после того, как файл был закрыт.
Метод file.flush() в Python, очищает буфер чтения.
Метод file.flush() очищает внутренний буфер. Обычно используется только для выходного потока. Его цель — очистить выходной буфер и переместить буферизованные данные на диск.
Метод file.fileno() в Python, получает файловый дескриптор.
Метод файла file.fileno() возвращает целочисленный файловый дескриптор, который используется базовой реализацией для запроса операций ввода-вывода из операционной системы.
Метод file.isatty() в Python, проверяет связь с терминалом.
Метод файла file.isatty() возвращает True, если файл подключен/связан с терминальным устройством tty или с tty-подобным устройством, иначе возвратит False.
Метод file.read() в Python, читает весь файл или кусками.
Метод файла file.read() считывает из файла не более size байтов. Если достигается конец файла EOF до получения указанного размера size байтов, тогда метод считает только доступные байты.
Метод file.readline() в Python, читает файл построчно.
Метод файла file.readline() читает одну целую строку из файла. Конечный символ новой строки \n сохраняется в строке.
Метод file.readlines() в Python, получает список строк файла.
Метод файла file.readlines() читает файловый объект построчно, пока не достигнет конца файла EOF, и возвращает список, содержащий строки файла.
Метод file.seek() в Python, перемещает указатель в файле.
Метод файла file.seek() устанавливает текущую позицию offset указателя для чтения/записи в файле file.
Метод file.tell() в Python, позиция указателя в файле.
Метод файла file.tell() возвращает текущую позицию указателя чтения/записи в файле в байтах.
Метод file.truncate() в Python, усекает размер файла.
Метод файла file.truncate() усекает размер файла. Если указан необязательный аргумент size, файл усекается до этого (максимально) размера.
Метод file.write() в Python, пишет данные в файл.
Метод файла file.write() записывает строку str в файл file. Метод возвращает целое число — количество записанных байт.
Метод file.writelines() в Python, пишет список строк в файл.
Метод файла file.writelines() записывает последовательность строк в файл file.
Файлы в Python
В целом различают два типа файлов (и работы с ними):
- текстовые файлы со строками неопределенной длины;
- двоичные (бинарные) файлы (хранящие коды таких данных, как, например, рисунки, звуки, видеофильмы);
Этапы работы с файлом:
- открытие файла;
- режим чтения,
- режим записи,
- режим добавления данных.
работа с файлом;
закрытие файла.
В python открыть файл можно с помощью функции open с двумя параметрами:
- имя файла (путь к файлу);
- режим открытия файла:
- «r» – открыть на чтение,
- «w» – открыть на запись (если файл существует, его содержимое удаляется),
- «a» – открыть на добавление.
В коде это выглядит следующим образом:
Fin = open ( "input.txt" ) Fout = open ( "output.txt", "w" ) # работа с файлами Fout.close() Fin.close() |
Работа с текстовыми файлами в Питон
Чтение из файла происходит двумя способами:
- построчно с помощью метода readline:
файл input.txt:
1
2
3
str1 = Fin.readline() # str1 = 1 str2 = Fin.readline() # str2 = 2 |
метод read читает данные до конца файла:
файл input.txt:
1
2
3
str = Fin.read() ''' str = 1 2 3 ''' |
Для получения отдельных слов строки используется метод split, который по пробелам разбивает строку на составляющие компоненты:
str = Fin.readline().split() print(str) print(str1) |
Пример:
В файле записаны два числа. Необходимо суммировать их.
файл input.txt:
12 17
ответ:
27
Решение:
- способ:
Fin = open ( "D:/input.txt" ) str = Fin.readline().split() x, y = int(str), int(str1) print(x+y) |
способ:
... x, y = int(i) for i in s print(x+y) |
* Функция int преобразует строковое значение в числовое.
В python метод write служит для записи строки в файл:
Fout = open ( "D:/out.txt","w" )
Fout.write ("hello")
|
Запись в файл можно осуществлять, используя определенный
шаблон вывода. Например:
Fout.write ( "{:d} + {:d} = {:d}\n".format(x, y, x+y) )
|
В таком случае вместо шаблонов {:d} последовательно подставляются значения параметров метода format (сначала x, затем y, затем x+y).
Аналогом «паскалевского» eof (если конец файла) является обычный способ использования цикла while или с помощью добавления строк в список:
-
while True: str = Fin.readline() if not str: break
-
Fin = open ( "input.txt" ) lst = Fin.readlines() for str in lst: print ( str, end = "" ) Fin.close() - подходящий способ для Python:
for str in open ( "input.txt" ): print ( str, end = "" ) |
Задание Python 9_1:
Считать из файла input.txt 10 чисел (числа записаны через пробел). Затем записать их произведение в файл output.txt.
Рассмотрим пример работы с массивами.
Пример:
Считать из текстового файла числа и записать их в другой текстовый файл в отсортированном виде.
Решение:
- Поскольку в Python работа с массивом осуществляется с помощью структуры список, то количество элементов в массиве заранее определять не нужно.
- Считывание из файла чисел:
lst = while True: st = Fin.readline() if not st: break lst.append (int(st)) |
Сортировка.
Запись отсортированного массива (списка) в файл:
Fout = open ( "output.txt", "w" ) Fout.write (str(lst)) # функция str преобразует числовое значение в символьное Fout.close() |
Или другой вариант записи в файл:
for x in lst:
Fout.write (str(x)+"\n") # запись с каждой строки нового числа
|
Задание Python 9_2:
В файле записаны в целые числа. Найти максимальное и минимальное число и записать в другой файл.
Задание Python 9_3:
В файле записаны в столбик целые числа. Отсортировать их по возрастанию суммы цифр и записать в другой файл.
Рассмотрим на примере обработку строковых значений.
Пример:
В файл записаны сведения о сотрудниках некоторой фирмы в виде:
Иванов 45 бухгалтер
Необходимо записать в текстовый файл сведения о сотрудниках, возраст которых меньше 40.
Решение:
- Поскольку сведения записаны в определенном формате, т.е. вторым по счету словом всегда будет возраст, то будем использовать метод split, который разделит слова по пробелам. Под номером 1 в списке будет ити возраст:
st = Fin.readline() data = st.split() stAge = data1 intAge = int(stAge) |
Более короткая запись будет выглядеть так:
st = Fin.readline() intAge = int(st.split()1) |
Программа выглядит так:
while True: st = Fin.readline() if not s: break intAge = int (st.split()1) |
Но лучше в стиле Python:
for st in open ( "input.txt" ):
intAge = int (st.split()1)
if intAge < 5:
Fout.write (st)
|
Задание Python 9_4:
В файл записаны сведения о детях детского сада:
Иванов иван 5 лет
Необходимо записать в текстовый файл самого старшего и самого младшего.
Чтение документов MS Word
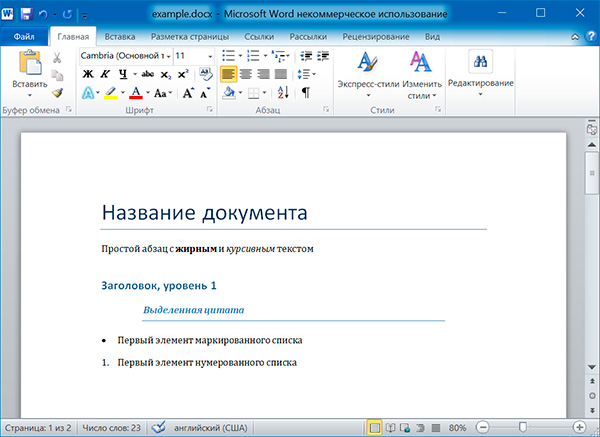
Файлы с расширением .docx обладают развитой внутренней структурой. В модуле python-docx эта структура представлена тремя различными типами данных. На самом верхнем уровне объект представляет собой весь документ. Объект содержит список объектов , которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов , представляющих собой фрагменты текста с различными стилями форматирования.

import docx
doc = docx.Document('example.docx')
# количество абзацев в документе
print(len(doc.paragraphs))
# текст первого абзаца в документе
print(doc.paragraphs.text)
# текст второго абзаца в документе
print(doc.paragraphs1.text)
# текст первого Run второго абзаца
print(doc.paragraphs1.runs.text)
6 Название документа Простой абзац с жирным и курсивным текстом Простой абзац с
Получаем весь текст из документа:
text =
for paragraph in doc.paragraphs
text.append(paragraph.text)
print('\n'.join(text))
Название документа Простой абзац с жирным и курсивным текстом Заголовок, уровень 1 Выделенная цитата Первый элемент маркированного списка Первый элемент нумерованного списка
Стилевое оформление
В документах MS Word применяются два типа стилей: стили абзацев, которые могут применяться к объектам , стили символов, которые могут применяться к объектам . Как объектам , так и объектам можно назначать стили, присваивая их атрибутам значение в виде строки. Этой строкой должно быть имя стиля. Если для стиля задано значение , то у объекта или не будет связанного с ним стиля.
Стили символов
paragraph.style = 'Quote' run.style = 'Book Title'
Атрибуты объекта Run
Отдельные фрагменты текста, представленные объектами , могут подвергаться дополнительному форматированию с помощью атрибутов. Для каждого из этих атрибутов может быть задано одно из трех значений: (атрибут активизирован), (атрибут отключен) и (применяется стиль, установленный для данного объекта ).
- — Полужирное начертание
- — Подчеркнутый текст
- — Курсивное начертание
- — Зачеркнутый текст
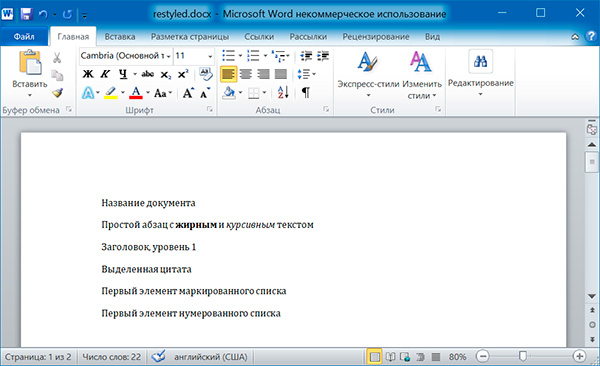
Изменим стили для всех параграфов нашего документа:
import docx
doc = docx.Document('example.docx')
# изменяем стили для всех параграфов
for paragraph in doc.paragraphs
paragraph.style = 'Normal'
doc.save('restyled.docx')
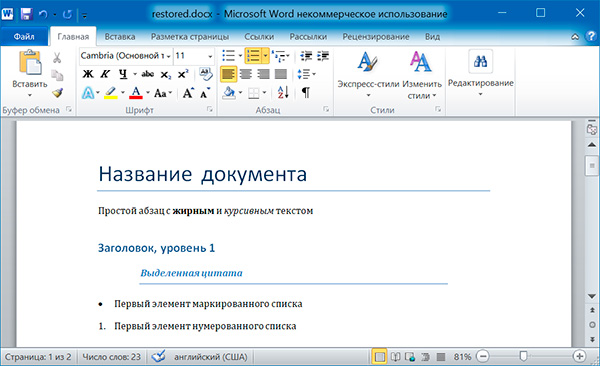
А теперь восстановим все как было:
import docx
os.chdir('C:\\example')
doc1 = docx.Document('example.docx')
doc2 = docx.Document('restyled.docx')
# получаем из первого документа стили всех абзацев
styles =
for paragraph in doc1.paragraphs
styles.append(paragraph.style)
# применяем стили ко всем абзацам второго документа
for i in range(len(doc2.paragraphs))
doc2.paragraphsi.style = stylesi
doc2.save('restored.docx')
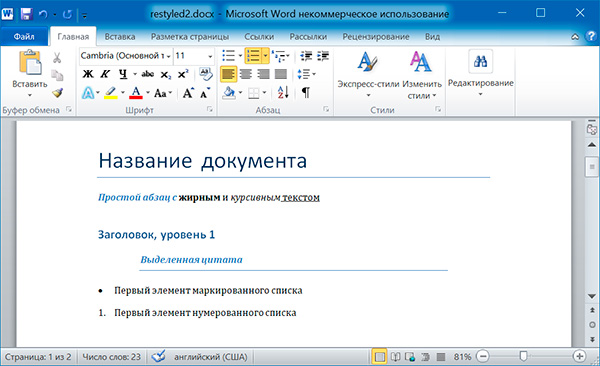
Изменим форматирвание объектов второго абзаца:
import docx
doc = docx.Document('example.docx')
# добавляем стиль символов для runs
doc.paragraphs1.runs.style = 'Intense Emphasis'
# добавляем подчеркивание для runs
doc.paragraphs1.runs4.underline = True
doc.save('restyled2.docx')
Обработка PDF документов
В Linux для работы с файлами PDF всё проще, есть мощные инструменты командной строки, такие как и . Но, поскольку, PDF — межплатформенный открытый формат электронных документов, хотелось бы с таким же удобством работать и в Windows, и в macOS. При этого нужна фантазия и усилия разработчика. Вот и совсем недавно встретилась задачка переноса информации из PDF‑файла в базу данных. Естественно, задача автоматизации здесь имеет свою уникальную специфику и без разработки здесь ну совсем никак.
Это руководство — начало небольшой серии, где будут рассмотрены полезные для разработчика библиотеки, позволяющие создавать собственные скрипты Python для решения рутинных задач автоматизации
В первой части внимание сконцентрировано на манипулировании существующими PDF‑файлами. Вы узнаете, как читать и извлекать содержимое (текст и изображения) и разбивать документы на отдельные страницы
Вторая часть будет посвящена наложению водяных знаков в документ. Третья часть посвящена исключительно написанию/созданию PDF‑файлов, а также удалению и повторному объединению отдельных страниц в новый документ.
Способ 1
import os
import shutil
import glob
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
# получить список файлов в папке RandomFiles
files_to_group = []
for random_file in os.listdir('.'):
files_to_group.append(random_file)
# получить все расширения имен всех файлов
file_extensions = []
for our_file in files_to_group:
file_extensions.append(os.path.splitext(our_file))
print(set(file_extensions))
file_types = set(file_extensions)
for type in file_types:
new_directory = type.replace(".", " ")
os.mkdir(new_directory) # создать папку с именем данного расширения
for fname in glob.glob(f'*.{type}'):
shutil.move(fname, new_directory)
Для этого импортируем еще две библиотеки: shutil и glob. Первая поможет перемещать файлы, а вторая – находить и систематизировать. Но обо всем по порядку.
Для начала получим список всех файлов в директории.
Здесь мы предполагаем, что у нас нет ни малейшего понятия о том, какие именно файлы лежат в этой папке. Вместо того, чтобы вписывать все расширения вручную и использовать лестницу инструкций if или switch, мы желаем, чтобы программа сама просмотрела каталог и определила, на какие типы можно разделить его содержание. Что, если бы там были файлы с десятками расширений или логи? Вы бы стали описывать их вручную?
Получив список всех
файлов, мы заходим в еще один цикл, чтобы извлечь расширения названий.
Обратите внимание на разделение строки:
os.path.splitext(our_file)
Сейчас наша переменная выглядит как-нибудь так: . Когда разделим ее, получим следующее:
`('5', '.docx')`
Мы возьмем отсюда второй элемент по индексу , то есть . Ведь по индексу у нас располагается 5.
Таким образом, у нас имеется список всех файловых расширений в папке, в том числе повторяющихся. Чтобы оставить только уникальные элементы, преобразуем его во множество. К примеру, если бы этот список состоял исключительно из , повторяющегося снова и снова, то в set остался бы всего один элемент.
# создать множество и присвоить его переменной file_types = set(file_extensions)
Заметим, что в списке типов файлов каждое расширение содержит в начале. Если мы назовем так папки на UNIX-системе, то они будут скрытыми, что не входит в наши намерения.
Поэтому, итерируя
по нашему множеству, мы заменяем точку на пустую строку. И создаем папку с полученным
названием.
new_directory = type.replace(".", " ")
# наша директория теперь будет называться "docx"
Но чтобы переместить файлы, нам все еще нужно расширение .
for fname in glob.glob(f'*.{type}')
Этим попросту отбираем все файлы, оканчивающиеся расширением . Заметьте, что в нет пробелов.
Символ подстановки обозначает, что подходит любое имя, если оно заканчивается на . Поскольку мы уже включили точку в поиск, мы используем , что значит «все после первого символа». В нашем примере это .
Что дальше?
Перемещаем любые файлы с данным расширением в директорию с тем же названием.
shutil.move(fname, new_directory)
Таким образом, как только в цикле создана папка для первого попавшегося файла с данным расширением, все последующие файлы будут отправлены в нее же. Все будет сгруппировано без повторения каталогов.
Как читать файлы
Python содержит в себе функцию, под названием «open», которую можно использовать для открытия файлов для чтения. Создайте текстовый файл под названием test.txt и впишите:
Python
This is test file
line 2
line 3
this line intentionally left lank
|
1 |
This is test file line 2 line 3 this line intentionally left lank |
Вот несколько примеров того, как использовать функцию «открыть» для чтения:
Python
handle = open(«test.txt»)
handle = open(r»C:\Users\mike\py101book\data\test.txt», «r»)
|
1 |
handle=open(«test.txt») handle=open(r»C:\Users\mike\py101book\data\test.txt»,»r») |
В первом примере мы открываем файл под названием test.txt в режиме «только чтение». Это стандартный режим функции открытия файлов
Обратите внимание на то, что мы не пропускаем весь путь к файлу, который мы собираемся открыть в первом примере. Python автоматически просмотрит папку, в которой запущен скрипт для text.txt
Если его не удается найти, вы получите уведомление об ошибке IOError. Во втором примере показан полный путь к файлу, но обратите внимание на то, что он начинается с «r». Это значит, что мы указываем Python, чтобы строка обрабатывалась как исходная. Давайте посмотрим на разницу между исходной строкой и обычной:
Python
>>> print(«C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data est.txt
>>> print(r»C:\Users\mike\py101book\data\test.txt»)
C:\Users\mike\py101book\data\test.txt
|
1 |
>>>print(«C:\Users\mike\py101book\data\test.txt») C\Users\mike\py101book\data est.txt >>>print(r»C:\Users\mike\py101book\data\test.txt») C\Users\mike\py101book\data\test.txt |
Как видно из примера, когда мы не определяем строку как исходную, мы получаем неправильный путь. Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Введите нижеизложенные строки в скрипт, и сохраните его там же, где и файл test.txt.
Python
handle = open(«test.txt», «r»)
data = handle.read()
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.read() print(data) handle.close() |
После запуска, файл откроется и будет прочитан как строка в переменную data. После этого мы печатаем данные и закрываем дескриптор файла. Следует всегда закрывать дескриптор файла, так как неизвестно когда и какая именно программа захочет получить к нему доступ. Закрытие файла также поможет сохранить память и избежать появления странных багов в программе. Вы можете указать Python читать строку только раз, чтобы прочитать все строки в списке Python, или прочесть файл по частям. Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Давайте обратим внимание на различные способы чтения файлов. Python
handle = open(«test.txt», «r»)
data = handle.readline() # read just one line
print(data)
handle.close()
Python
handle = open(«test.txt», «r»)
data = handle.readline() # read just one line
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.readline()# read just one line print(data) handle.close() |
Если вы используете данный пример, будет прочтена и распечатана только первая строка текстового файла. Это не очень полезно, так что воспользуемся методом readlines() в дескрипторе:
Python
handle = open(«test.txt», «r»)
data = handle.readlines() # read ALL the lines!
print(data)
handle.close()
|
1 |
handle=open(«test.txt»,»r») data=handle.readlines()# read ALL the lines! print(data) handle.close() |
После запуска данного кода, вы увидите напечатанный на экране список, так как это именно то, что метод readlines() и выполняет. Далее мы научимся читать файлы по мелким частям.
Альтернатива для модуля glob
Помимо модулей , в Python также доступен модуль , что предоставляет путь связанных утилит. Функция модуля используется для нахождения файлов, соответствующих шаблону.
Python
from glob import glob
top_xlsx_files = glob(‘*.xlsx’) # Все файлы с расширением .xlsx
all_xlsx_files = glob(‘**/*.xlsx’, recursive=True)
|
1 |
fromglobimportglob top_xlsx_files=glob(‘*.xlsx’)# Все файлы с расширением .xlsx all_xlsx_files=glob(‘**/*.xlsx’,recursive=True) |
Pathlib предоставляет свою реализацию :
Python
from pathlib import Path
top_xlsx_files = Path.cwd().glob(‘*.xlsx’)
all_xlsx_files = Path.cwd().rglob(‘*.xlsx’)
|
1 |
frompathlib importPath top_xlsx_files=Path.cwd().glob(‘*.xlsx’) all_xlsx_files=Path.cwd().rglob(‘*.xlsx’) |
Функциональность glob доступна с объектами . Следовательно, модуль Pathlib упрощают сложные задачи.
Чтение и запись в бинарном режиме доступа
Что такое
бинарный режим доступа? Это когда данные из файла считываются один в один без
какой-либо обработки. Обычно это используется для сохранения и считывания
объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
books =
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
Откроем файл на
запись в бинарном режиме:
file = open("out.bin", "wb")
Далее, для работы
с бинарными данными подключим специальный встроенный модуль pickle:
import pickle
И вызовем него
метод dump:
pickle.dump(books, file)
Все, мы
сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на
чтение в бинарном режиме:
file = open("out.bin", "rb")
и далее вызовем
метод load модуля pickle:
bs = pickle.load(file)
Все, теперь
переменная bs ссылается на
эквивалентный список:
print( bs )
Аналогичным
образом можно записывать и считывать сразу несколько объектов. Например, так:
import pickle
book1 = "Евгений Онегин", "Пушкин А.С.", 200
book2 = "Муму", "Тургенев И.С.", 250
book3 = "Мастер и Маргарита", "Булгаков М.А.", 500
book4 = "Мертвые души", "Гоголь Н.В.", 190
try:
file = open("out.bin", "wb")
try:
pickle.dump(book1, file)
pickle.dump(book2, file)
pickle.dump(book3, file)
pickle.dump(book4, file)
finally:
file.close()
except FileNotFoundError:
print("Невозможно открыть файл")
А, затем,
считывание в том же порядке:
file = open("out.bin", "rb")
b1 = pickle.load(file)
b2 = pickle.load(file)
b3 = pickle.load(file)
b4 = pickle.load(file)
print( b1, b2, b3, b4, sep="\n" )
Вот так в Python выполняется
запись и считывание данных из файла.







