Онлайн сервис восстановления сайтов из веб архива
Содержание:
- Как посмотреть сайт в прошлом: полная историческая проверка
- archive.md
- HTML верстка и анализ содержания сайта
- Просмотр истории посещения в браузере:
- Петля времени: можно ли вернуться в прошлое?
- Как посмотреть, как раньше выглядела страница «ВКонтакте» через поиск Google?
- Смотрим каким был сайт ранее
- Этап второй: База Данных
- Зачем был придуман первый веб-сайт
- Проекты, предоставляющие историю сайта
- Как посмотреть, как раньше выглядела страница «ВКонтакте» через Internet Archive?
- Что такое Wayback Machine и Архивы Интернета
- Что такое кэш и как он работает
- Для чего нужны сохраненные страницы?
- Как из Интернета скопировать видео
Как посмотреть сайт в прошлом: полная историческая проверка
Рад приветствовать вас на блоге. Огромное число сайтов работает на просторах интернета. У каждого есть своя история создания и изменения. Можно ли ее посмотреть и насколько глубоко?
Сегодня покажу, как посмотреть сайт в прошлом при помощи специальных инструментов и сервисов. Сделать это можно при помощи 3 способов. Про них желательно знать каждому вебмастеру еще до оформления домена, так как его история может повлиять на дальнейшее продвижение ресурса.
Сохраненные копии сайта в поисковых системах
Сейчас опишу один из самых простых подходов. Знакомы с поисковыми системами Яндекс и Google. Благодаря их возможностям, можно посмотреть содержание страницы и внешний вид сайта в недалеком прошлом. Как же это сделать?
Опишу порядок действий по пунктам.
- Вводим адрес страницы и выполняем поиск.
- Нажимаем на треугольник и открываем контекстное меню (показано стрелкой на картинке).
- Переходим к сохраненной копии. Сверху указывается дата её сохранения.
Как видите, ничего сложного нет. Однако стоит учесть, что для применения описанного способа искомый url должен находится в индексе поисковика.
Просмотр изменений на сайте в архивах интернета
Я раньше долго искал, где можно посмотреть изменения ресурсов во времени в наглядном виде. Нашел. Сейчас продемонстрирую его работу на примере своего блога. Покажу его состояние в 2014 году, а внешний облик на 2016 год можете наблюдать прямо сейчас.
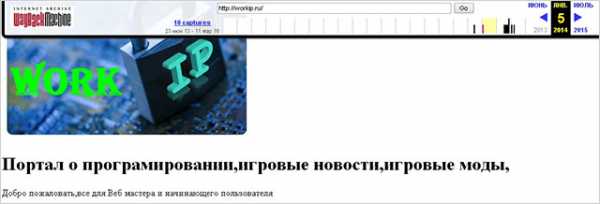
Судя по всему, в 2014 здесь был какой-то портал о программировании и играх. Похоже, он был закрыт, так как домен я приобрел в 2015 году. Вот только заметил я эту особенность после покупки. После обнаружения я провел подробный анализ ситуации и решил, что доменное имя можно оставить, так как с его репутацией было все в порядке.
На заметку — для продвижения новых проектов я рекомендую брать адреса с чистой историей. Можно взять url и с солидным прошлым в случае, когда тематика «предшественников» была близка к текущей, а репутация положительная. Найти такие домены по обычной цене — это редкость.
Возвращаясь к основной теме, покажу, где можете посмотреть содержание электронного ресурса на состояние минувших лет. Распишу пошаговую последовательность действий.
- Открываем http://archive.org/web/.
- Вводим название домена и запускаем поиск.
- Выбираем одну из доступных для просмотра дат и смотрим исторические сведения.
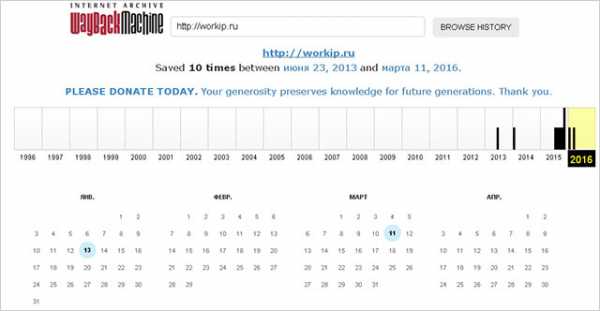
Как видите на скриншоте, конкретно для моего проекта для просмотра доступны данные, начиная с 2013 года.
Дата создания сайта
Как ее узнать? Для просмотра даты регистрации доменного имени можно пользоваться специальным сервисом — http://www.whois-service.ru/. Для поиска я введу свой домен и среди прочих результатов вижу строки, показанные на картинке ниже.
На иллюстрации видно, что регистрация была совершена в 2015 году, а оплата до мая 2017. Если внимательно читали статью, то знаете, что визуально прошлое моего домена можно увидеть с 2013, однако этой даты в результатах нет. В принципе все правильно — отображается актуальная информация о действующей регистрации.
История домена
Как же заглянуть дальше в прошлое? Для этого понадобится история изменения параметров Whois для конкретного адреса. Будет полезен представленный ниже сервис. Чтобы посмотреть всю историю домена сайта, можно сделать в следующем порядке:
- Открываем https://www.nic.ru/whois/.
- Выполняем запрос по доменному имени.
- Под появившейся информацией выбираем соответствующий пункт.
- Смотрим список результатов.
Кстати, благодаря таким возможностям я обнаружил, что прошлое моего url (workip.ru) начинается аж с 2010 года.
История изменения параметров сайта
Еще один важный нюанс — знаете, как проверить изменение ТИЦ? Данная возможность доступна здесь http://www.recipdonor.com/. Нужно будет зарегистрироваться, проверка платная, однако я считаю, что расценки не высокие
После регистрации и изучения проекта следует обратить внимание на инструмент «история параметров»
Как можете наблюдать, можно получить данные только по интересующим пунктам.
В заключении отмечу, что для анализа исторических данных могут применяться и другие сервисы. Выбор остается за пользователем.
Теперь вы владеете эффективной информацией о том, как посмотреть любой из сайтов в прошлом времени, узнать дату его создания и изменение параметров. Как вы могли убедиться, узнать исторические сведения не сложно. В идеале, репутацию домена желательно проверять еще на этапе его выбора.
Не прощаюсь. Новые материалы появятся уже скоро. Подписывайтесь на обновления блога Workip. До связи.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
HTML верстка и анализ содержания сайта
Размещённая в данном блоке информация используется оптимизаторами для контроля наполнения контентом главной страницы сайта, количества ссылок, фреймов, графических элементов, объёма теста, определения «тошноты» страницы.
Отчёт содержит анализ использования Flash-элементов, позволяет контролировать использование на сайте разметки (микроформатов и Doctype).
IFrame – это плавающие фреймы, которые находится внутри обычного документа, они позволяет загружать в область заданных размеров любые другие независимые документы.
Flash — это мультимедийная платформа компании для создания веб-приложений или мультимедийных презентаций. Широко используется для создания рекламных баннеров, анимации, игр, а также воспроизведения на веб-страницах видео- и аудиозаписей.
Микроформат — это способ семантической разметки сведений о разнообразных сущностях (событиях, организациях, людях, товарах и так далее) на веб-страницах с использованием стандартных элементов языка HTML (или XHTML).
Просмотр истории посещения в браузере:
Chrome
Вариант №1
Нажать простое сочетание кнопок Ctrl+H — должно автоматически открыться окно с историей (прим.: H — History).
Вариант №2
Достаточно скопировать адрес: chrome://history/ и вставить его в адресную строку браузера. Просто и легко!
Вариант №3
В правом верхнем углу окна браузера нужно нажать значок с «тремя точками» — в открывшемся списке выбрать вкладку «История» (см. скриншот ниже).
Далее пред вами откроется полный список всех посещений: по датам, времени (см. пример ниже). Также можно искать нужно страничку по ее названию (верхнее меню).
В общем-то, довольно быстро можно найти те сайты, на которые вы заходили…
Opera
Вариант №1
Зажать одновременно кнопки Ctrl+H (также, как и в Chrome).
Вариант №2
Нажать в левом верхнем углу «Меню» и выбрать вкладку «История». Далее у вас будет возможность:
- открыть журнал (историю посещений);
- очистить историю посещений (кстати, для этого также можно зажать кнопки Ctrl+Shift+Del);
- либо просмотреть несколько последних просмотренных страничек (пример ниже).
Кстати, сам журнал, на мой взгляд, даже поудобнее чем в Chrome. Здесь также можно искать в истории по определенному названию странички, сбоку есть удобный рубрикатор по датам: сегодня/вчера/старые.
Firefox
Вариант №1
Для вызова окна журнала посещений необходимо нажать сочетание кнопок Ctrl+Shift+H.
Вариант №2
Также вызвать журнал можно обратившись к меню: в правом верхнем углу нужно на значок с «тремя линиями» — в открывшемся под-окне выбрать «Журнал» (см. скрин ниже ).
Кстати, в Firefox журнал посещений (см. скрин ниже), на мой взгляд, выполнен почти идеально: можно смотреть сегодняшнюю историю, вчерашнюю, за последние 7 дней, за этот месяц и пр.
Можно сделать резервную копию, или экспортировать/импортировать записи. В общем-то, все что нужно — под рукой!
Edge
Вариант №1
Нажать сочетание кнопок на клавиатуре Ctrl+H — в правом верхнем окне программы откроется небольшое боковое меню с журналом (пример на скрине ниже).
Вариант №2
Нажать по меню «Центр» (находится в правом верхнем углу программы), затем переключить вкладку с избранного на журнал (см. цифру-2 на скрине ниже).
Собственно, здесь можно и узнать всю необходимую информацию (кстати, здесь же можно очистить историю посещений).
Петля времени: можно ли вернуться в прошлое?
Может ли знаменитый «парадокс убитого дедушки», описанный Рене Баржавелем еще в 1943 году, стать реальностью?
28 июня 2009 года всемирно известный физик Стивен Хокинг устроил вечеринку в Кембриджском университете, с воздушными шарами, закусками и шампанским. Однако на нее никто не явился, потому что Хокинг разослал приглашения только после окончания вечеринки. Это был, по его словам, «торжественный прием для путешественников во времени» — тем самым физик хотел укрепить свою давнюю гипотезу, что путешествия во времени невозможны.
Но Хокинг мог и ошибаться. Теоретически никаких прямых запретов на путешествия в прошлое нет. Это трюк может стать возможным на основе общей теории относительности Эйнштейна, которая описывает гравитацию как искривления пространства и времени по энергии и материи. Чрезвычайно мощное гравитационное поле, образованное, например, вращающейся черной дырой, может деформировать материю так, что пространство будет искривлено «наизнанку». Это создало бы так называемую замкнутую времениподобную кривую — цикл, который фактически будет являться путешествием во времени.
Хокинг и многие другие физики считают замкнутую времениподобную кривую абсурдной, потому что путешествия во времени любого макроскопического объекта неизбежно создают парадоксы, которые ломают причинно-следственную связь.
Но недавно физик из Университета Квинсленда (Австралия) Тим Ральф и его аспирант Мартин Рингбауэр попытались исследовать «парадокс убитого дедушки» с точки зрения квантовой механики.
Суть парадокса заключается в том, чтобы вернуться в прошлое и убить собственного деда, тем самым предотвратив собственное рождение. Согласно гипотезе, что прошлое изменить никак нельзя, дед уже должен был пережить покушение на убийство, либо путешественник во времени создает тем самым альтернативную линию времени, в которой он никогда не будет рожден.
С точки зрения квантовой механики, если представить человека как фундаментальную частицу, то ее априори детерминированной эмиссии не существует — есть лишь распределение вероятностей. То есть, человек с равной вероятностью как совершил бы убийство, так и дал бы своему деду шанс на спасение — а этого достаточно, чтобы замкнуть кривую и избежать парадокса, отмечают австралийские исследователи.
Как посмотреть, как раньше выглядела страница «ВКонтакте» через поиск Google?
В данной статье мы рассмотрим способы просмотра старых копий страниц, но здесь нужно отметить, что таким способом можно посмотреть только профили тех людей, что не были скрыты настройками приватности, которые закрывают страницу от поисковых систем. При этом здесь можно посмотреть даже те страницы, что ранее были удалены.
Сначала мы расскажем о том, как посмотреть старую версию страницы, пользуясь популярным поисковиком Google, который умеет сохранять различные страницы в Интернете в их ранних версиях. Но здесь нужно понимать, что все эти сохраненные страницы остаются в памяти поисковика на ограниченный период времени, то есть старая версия удаляется после того, как она будет сканирована снова.
В поисковой строке нужно ввести запрос с именем человека «ВКонтакте», а также со специальным добавлением site:vk.com, чтобы Google показывал результаты только внутри этой социальной сети. В поисковой выдаче далее нужно найти требуемую страницу и рядом с нею нажать на кнопку с зеленым треугольником, чтобы открыть меню с дополнительными функциями. Далее в отобразившемся списке нужно выбрать пункт «Сохраненная копия».
После этого пользователь попадет на страницу искомого человека, причем на ту ее версию, что сканировалась поисковиком Google в предыдущий раз. В зависимости от того, насколько старая версия в итоге откроется, может изменяться даже сам интерфейс социальной сети «ВКонтакте».
Также стоит отметить, что даже если пользователь уже авторизовался в этой социальной сети, он увидит данную страницу со стороны человека, которые не зарегистрирован «ВКонтакте», то есть как анонимный посетитель, потому что именно так видят профили на данном сайте роботы Google. Если же пользователь решит зайти в свой профиль, чтобы подробнее просмотреть материалы, размещенные на сохраненной версии найденной страницы, он просто попадет на оригинальную текущую версию «ВКонтакте». Это значит, что таким способом можно посмотреть только ту основную информацию, что была размещена непосредственно на самой странице человека, а все остальные дополнительные материалы просто не получится открыть. Именно поэтому здесь нельзя будет, например, просмотреть список подписчиков или все фотографии человека. Также стоит заметить, что смотреть старые сохраненные версии профилей известных и популярных людей в этой социальной сети, по сути, не имеет никакого смысла, потому что на эти страницы заходит слишком много людей, а потому они намного чаще сканируются поисковыми системами.
Смотрим каким был сайт ранее
Итак, как же посмотреть сохранённые копии сайтов? Воспользуемся возможностями данного проекта и попробуем приоткрыть покровы времени.
- Введите в поисковой строке адрес интересующего вас сайта (например, www.youtube.com):
- И нажмите на кнопку «Browse history» (просмотреть историю) справа.
Система обработает запрос и выдаст вам результат. Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.
История сайта за 2005 год
Выберите дату сохранённого сервисом скриншота
Кликните, к примеру, на самый ранний год (в случае Ютуб это 2005 год), внизу отобразится полный календарь данного года по месяцам. Дни, когда были сделаны «снимки» сайта будут подсвечены голубоватым цветом, в нашем случае первый «снимок» был сделан 28 апреля данного года.
Кликаем на 28 апреля и просматриваем, как выглядел сервис Youtube 28 апреля 2005 года.
Соответствующим образом вы можете просмотреть любой из интересующих вас сайтов.
Также можно работать с данным сервисом напрямую, введя в адресной строке вашего браузера:
http://web.archive.org/web/*/http://url нужного сайта
Например:
http://web.archive.org/web/*/http://google.com
Соответственно, введя данную строку в адресной строке браузера и нажав на ввод, вы сразу попадёте в отображение снимков нужного вам сайта по годам, месяцам и днём.
Этап второй: База Данных
Для восстановления состояния базы, сохраненной вручную, необходимо импортировать файл резервной копии в БД, с которой работает сайт. Сделать это можно двумя способами:
Восстановление базы, способ №1: phpMyAdmin
- WordPress — /wp-config.php
- Joomla — /configuration.php
- MODx — /core/config/config.inc.php либо /manager/includes/config.inc.php
- OpenCart — /config.php и /admin/config.php (обязательно править оба)
- Prestashop — /config/settings.inc.php
- PHPShop — /phpshop/inc/config.ini
- 1C-Bitrix — /bitrix/php_interface/dbconn.php
- Drupal — /sites/default/settings.php
- DLE — /engine/data/dbconfig.php
- HostCMS — /hostcmsfiles/config_db.php
- InstantCMS — /includes/config.inc.php
- Amiro — /_local/config.ini.php
- vBulletin — /include/config.php
- WebAsyst — /kernel/wbs.xml
- Magento — /app/etc/local.xml
- Invision Power Board — /conf_global.php
Затем переходим в раздел MySQL и по клику на соответствующую иконку открываем phpMyAdmin.
Обратите внимание!
Всплывающие окна для cp.beget.com сайта в браузере должны быть разрешены!
Также не забывайте о нашем Руководстве: подробную информацию по этому разделу Панели управления Вы можете получить там.

Теперь нам нужно загрузить нашу резервную копию в БД. Нажмите вкладку «Импорт», выберите файл созданной резервной копии на Вашем компьютере с помощью кнопки «Обзор» и нажмите кнопку «Вперёд»:
Начнется процесс загрузки резервной копии в БД. Он может занять продолжительное время, в зависимости от объема Вашей БД и скорости Вашего интернет-соединения. Если при импорте резервной копии через phpMyAdmin у Вас возникают ошибки (такое возможно, если файл резервной копии достаточно большой) — попробуйте второй способ восстановления.

После загрузки Вы увидите сообщение о том, что импорт произведен успешно.
Восстановление базы, способ №2: терминал
Все действия выполняются из каталога, в котором находится резервная копия. По умолчанию это корневая директория аккаунта. Если Вы не в корневой директории, перейти в неё можно простой командой:
Остается распаковать файл резервной копии командой gunzip:
Архив будет распакован, в той же папке будет создан файл с именем название_архива.sql. Остается лишь импортировать его в БД сайта командой:
На примере это будет выглядеть так:
Данные для подключения можно посмотреть в тех же конфигурационных файлах, о которых мы рассказали в первом способе.
Зачем был придуман первый веб-сайт
Главная страница сайта
Цель проекта банальна для эпохальной технологии на начальной стадии — упростить работу команде. Марк Цукерберг затем же создавал Facebook, чтобы ему и его одногруппникам было проще общаться друг с другом.
ЦЕРН отклонил идею, но Бернерс Ли проявил настойчивость и продолжил разрабатывать сайт, уже в команде с Робертом Кайо.
Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Ученый предложил сделать так, чтобы гипертекст был доступен одновременно нескольким компьютерам, подключенным к интернету.
«Меня расстраивало, на разных компьютерах содержалась разная информация. И чтобы получить к ней доступ к нескольким источникам, нужно задействовать несколько компьютеров», — говорил Бернерс Ли.
NeXT. Компьютер, на котором был создан первый веб-сайт.
У британца была и более масштабная задача. В ЦЕРН приезжали люди из университетов со всего мира, и привозили с собой компьютеры со всеми видами программного обеспечения. Проблемой была невозможность использования одной программы на компьютерах с разными видами софта.
Бернерс Ли искал ее решение. Изначально он думал о создании ряда программ, берущих информацию из одной системы и конвертирующих ее формат для показа в другой.
Но оптимизировать программы под каждый софт — долго, энергозатратно и дорого. Британец выбрал другой способ: просто дать доступ к информации всем сразу.
Проекты, предоставляющие историю сайта
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Как посмотреть, как раньше выглядела страница «ВКонтакте» через Internet Archive?
Этот способ отличается от вышеописанного тем, что в архиве нет никаких особых требований к тому, как именно должна выглядеть и быть настроенной страница, но при этом здесь есть не все профили, так как загружать в архив их нужно ручным способом. Для начала нужно перейти в сам архив по этой ссылке. Далее здесь в соответствующем поле нужно ввести непосредственно сам адрес к тому профилю, старую версию которого требуется посмотреть. Если поиск будет проведен успешно, то пользователь увидит специальную шкалу времени, а также календарь с разными датами обновлений сохраненных копий профиля. При этом нужно понимать, что непопулярные страницы реже сохраняются в этом архиве, либо не сохраняются здесь вовсе. На временной шкале здесь нужно просто переключаться между разными периодами активности. Далее в отобразившемся календаре следует выбрать требуемую дату, за которую нужно посмотреть копию страницы. Нажимать и смотреть можно только те даты, которые подсвечены в этом календаре. После наведения курсора мыши на нужную дату появятся также разные варианты с ссылками на время сохранения страницы. Здесь нужно просто выбрать правильное время, чтобы старая версия профиля открылась.
После этого пользователь попадет на выбранную страницу с указанными датой и временем. Если это достаточно старая дата, можно будет увидеть даже прошлый интерфейс сайта «ВКонтакте»
При этом важно заметить, что данный ресурс сканирует страницы на английском языке, поэтому здесь нет русских версий профилей «ВКонтакте». В то же время, если на странице публиковался контент на русском, он будет отображен именно в таком виде, то есть на английском языке будет только весь интерфейс сайта
Если же пользователь хочет посмотреть страницу на русском языке, он может прибегнуть к следующему методу, описанному в этой статье.
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Что такое кэш и как он работает
Функция встроена практически во все современные программы. Браузер сохраняет информацию, которую пользователь просматривает, чтобы сократить время на повторную загрузку контента. Все файлы хранятся в папке временного буфера обмена, которая чаще всего находится на диске C. Туда попадают: тексты, файлы html с данными о разверстке и картинки. Количество сохраненных материалов ограничено только объемом встроенной памяти компьютера и настройками отдельного браузера.
Cash необходим для ускорения работы системы. Каждый раз, когда владелец ПК открывает ссылку, браузер сохраняет всю опубликованную информацию по выбранному адресу. При повторном запросе того же адреса браузер находит необходимый файл в папке временных данных и загружает его, корректируя изменившуюся информацию. Это снижает потребление трафика и позволяет не перегружать линию. Каждый дубликат хранится в памяти устройства, поэтому пользователь может загрузить даже тот контент, который недоступен в интернете.
Поисковые системы также способны создавать копии в cash. Если владелец сайта удалил его или ресурс был заблокирован, пользователь все равно сможет посмотреть интересующую его страницу. На ней нельзя будет увидеть последние изменения или внести какие-либо правки. Также пользователи не смогут:
оставлять комментарии;
- оценивать записи;
- публиковать новые материалы.
Как найти кеш сайта в Google
Чтобы открыть копию в поисковике, в запросе необходимо ввести название сайта и интересующую статью. В найденных результатах выбрать подходящий вариант. Справа от адреса располагается стрелка, указывающая вниз. Нажав на нее, пользователь открывает дополнительные возможности. Чтобы загрузить файл из кэша Google, нужно нажать на кнопку “Сохраненная копия”. Браузер открывает новую вкладку, в которой отобразится интересующая страница. Можно открыть ресурс напрямую, без использования результатов выдачи: для этого ввести запрос cash.ссылка, Где слово “ссылка” — домен необходимого сервиса.
Поиск копии страницы в Яндекс
Механика работы cash на российском ресурсе не отличается от поисковика Google. Чтобы открыть интересующую копию сайта, нужно сделать запрос его домена. Рядом с адресом расположена стрелка, из которой выпадает меню расширенных возможностей. Для загрузки дубликата ресурса из кэша выбрать вариант “Сохраненная копия”. В открывшейся вкладке Яндекс всегда указывает дату загрузки отображенной версии сайта.
Для чего нужны сохраненные страницы?
Кэш-страницы сайта в поисковых системах позволяют увидеть, какую версию документа уже успели проиндексировать роботы поисковых систем и участвует ли страница в ранжировании. Грубо говоря, если страница начала сохраняться — это главный фактор пройденной индексации.
Бесплатный бэкап
В работе с сайтами, может возникнуть масса непредвиденных ситуаций. Особенно на стадии запуска проекта, на сайте частенько ведутся технические работы, предполагающие корректировку дизайна и текстовых блоков. В такие моменты не исключены ошибки, которые могут «положить» сайт или нарушить его работу, также могут пропасть тексты, изображения и так далее.
Большинству разработчиков знакомы такие ситуации и если не был проведен бэкап, а дешевый хостинг не позволяет сделать «откат», то все печально. Вот тут-то и приходит на помощь кэш сайтов — копия позволяет сохраниться и проверить, какие ошибки нужно исправить.
SEO-продвижение
Еще один случай, когда кеш придет на помощь, связан с текстами. Например, вы откорректировали текст, чтобы повысить его релевантность. Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Технические проблемы, просрочка оплаты и так далее
Часто интернет-ресурсы бывают недоступны из-за технических проблем на сервере, истечения срока оплаты хостинга и т.п. В этом случае попасть на сайт можно также через копию, которая хранится в кэше.
Как из Интернета скопировать видео
Порядок сохранения видеофайлов, размещенных в сети Интернет, зависит от особенностей этих файлов.
Всё видео в Интернете условно можно разделить на 2 основных вида :
– видеофайлы, предназначенные для просмотра на локальных компьютерах, предлагаемые для скачивания точно так же, как и обычные файлы. Такое видео недоступно для просмотра непосредственно на страницах сайтов и предлагается для скачивания на локальный компьютер. Только после этого его можно будет смотреть. Порядок загрузки таких видеофайлов из Интернета ничем не отличается от загрузки файлов другого типа (см. следующий пункт этой статьи);
– онлайн-видео – видео, предназначенное для просмотра непосредственно на страницах сайтов без предварительной загрузки на локальный компьютер пользователя. Примеры такого видео можно увидеть на таких широко известных сайтах как YouTube, Megogo и др.
Онлайн-видео скопировать из Интернета достаточно сложно. Как правило, на сайтах можно смотреть видео, но никаких ссылок на его копирование вы там не найдете. Для решения проблемы потребуется использование дополнительных средств. Описание некоторых из них изложено чуть ниже.
Но не любое онлайн-видео из Интернета можно скачать. Для успешного его сохранения на локальном компьютере необходимо знать адрес этого видео в Интернете
Обратите внимание, что адрес страницы сайта, на которой размещено видео, и адрес самого видео – это разные вещи. Многие сайты скрывают этот адрес, что делает копирование видео практически невозможным
В то же время видеохостинги, такие как YouTube и многие другие, не скрывают адреса размещенного на них видео.
Узнать адрес видео можно следующим образом:
– открыть страницу сайта, на которой размещено для просмотра онлайн-видео;
– запустить видео, дождавшись когда закончатся разные рекламные ролики и др.;
– щелкнуть правой кнопкой мышки по окошку, в котором отображается видео, и в открывшемся контекстном меню выбрать пункт «Копировать URL видео» или пункт с другим похожим названием, щелкнув по нему левой кнопкой мышки ( см. рисунок );
– должно появиться небольшое окошко с адресом видео. Этот адрес можно скопировать в буфер обмена Windows и затем вставить в любом другом месте. Порядок копирования через буфер обмена изложен в этой статье выше, в пункте о копировании текстовой информации из сети.
На сайте YouTube узнать адрес видео можно еще одним способом. Нужно открыть страницу с размещенным видео и нажать на пункт «Поделиться», размещенный под окошком с отображаемым видео. Появится строка с адресом видео.
Некоторые способы сохранения онлайн-видео на локальном компьютере:
1 . Использование онлайн-конвертеров .
Онлайн-конвертер – это специальный сайт, который предлагает услуги по преобразованию файлов одного формата в другой. Одним из качественных онлайн-конвертеров является сайт zamzar.com .
Порядок работы с ним следующий:
– перейти на вкладку “URL Converter” ( см. рисунок ниже );
– в поле «Step 1» указать адрес видео в сети Интернет (см. выше);
– в поле «Step 2» выбрать один из форматов, в который будет преобразовано видео (формат AVI подходит в большинстве случаев);
– в поле «Step 3» указать работающий ящик электронной почты;
– нажать кнопку «Convert».
Через некоторое время на указанный вами адрес электронной почты придет письмо, в котором будет специальная гиперссылка для загрузки. Пройдя по ней, вы обычным способом (см. следующий пункт этой статьи) скачаете на локальный компьютер нужный видеофайл.
У онлайн-конвертеров есть один существенный недостаток – размер видеофайлов, сохраняемых с их помощью с Интернета, строго ограничен. В случае с zamzar.com можно скачать только видео, размер которого не превышает 100 MB. Это ограничение можно снять, но только на платной основе.
2 . Использование специальных программ , устанавливаемых на локальном компьютере пользователя и выполняющих те же функции, что и онлайн-конвертеры, например, YoutubeDownloader .